SAP Data Services: Integrating with SAP Business Suite Sources
SAP Data Services (formerly SAP BusinessObjects Data Services, sometimes referred to as BODS) offers an enterprise solution for data integration, profiling, quality, and text processing that enables users to integrate, transform, and load data. SAP Data Services is a comprehensive extraction, transformation, and loading (ETL) tool that supports loading of structured and unstructured data from SAP and non-SAP data sources into any SAP HANA application. When an external ETL tool is required in an SAP landscape, SAP recommends that you use SAP Data Services. SAP Business Suite powered by SAP HANA offers an in-memory platform for reporting and analysis of business processes in real time with data extractors that are compatible with SAP Data Services.
There is no one-size-fits-all solution when deciding which approach to take when integrating SAP Data Services to SAP Business Suite systems. Your approach depends on your custom system landscape and licensing, as you may or may not already have access to SAP Data Services. Whether you choose to implement SAP Data Services or prefer an alternative, such as Direct Extractor Connection (DXC), you must be prudent in considering all the nuanced benefits and constraints that each approach presents. I highlight the intricacies that each option presents to guide you on your next data integration endeavor.
What Is SAP Data Services?
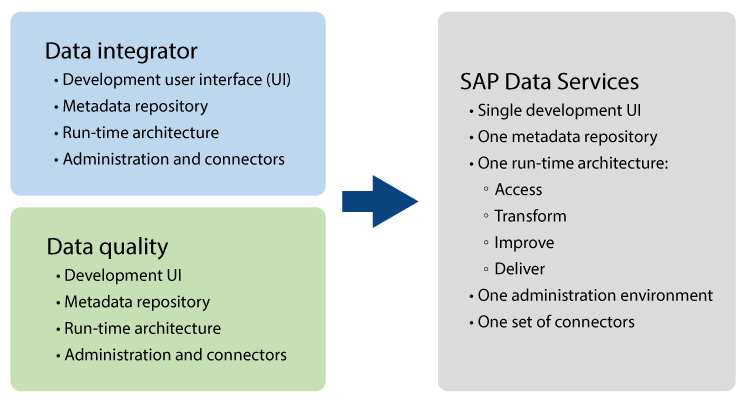
SAP Data Services combines the ability to execute data integration and ensure data quality and data cleansing. In general, the tool consists of the components shown in Figure 1. The data quality functionality includes the ability to standardize data, as well as to perform geo-coding and matching operations. The data-integration component offers profiling and auditing of data, and also analysis of text files. Aggregations, calculations, filtering, joins, and look-ups are all also possible with this interface.
Explore related questions
You can load data using SAP Data Services in many ways. For example, you can use basic Open Database Connectivity (ODBC) or Java Database Connectivity (JDBC) drivers to load from any data source, or you can load flat files through Application Programming Interfaces (APIs) and a variety of other interfaces, including SAP BW extractors.
One major new feature of SAP Data Services is the ability to execute data loading by leveraging the Operational Data Provisioning (ODP) for Replication API. This capability is now part of SAP BW and therefore a prerequisite on systems wanting to use this new ODP option. If a source system is on a recent Service Package (SP), the API is available for implementation. A list of the required SP levels is available within SAP Note 1521883. However, if the source system is on an older SP level, it may still be possible to use the ODP API with some limitations, as indicated in the SAP Note.
Not all extractors are supported in the ODP API. For example, hierarchy type extractors are not supported (but other SAP Data Services functionality can be used in this case). Also, ODP API extractors from SAP NetWeaver versions prior to SAP ERP 6.0 or SAP NetWeaver 7.0 are not supported. When you use the ODP API, there usually are two delta queues—one for the SAP BW system and one for SAP Data Services.
SAP Data Services is also compatible with a variety of applications, databases, file formats, and legacy systems. The complete list is shown in Table 1 (X denotes that the system is not supported).
|
Application |
Database |
Files or |
Mainframe |
Unstructured |
|
SAP HANA |
SAP Business Suite (extractors, ABAP, Business Application Programming Interface [BAPI], and IDoc) |
Text delimited |
Software AG |
Any text |
|
Oracle 11and 12 |
SAP BW |
Text fixed width |
Indexed Sequential |
Six languages |
|
IBM DB2 (Linux, Unix, Windows [LUW], z/OS, and iSeries) |
J.D. Edwards |
Extended Binary |
Virtual Storage |
Extended to |
|
Sybase ASE |
Oracle applications |
XML |
Enscribe |
X |
|
Sybase IQ |
PeopleSoft |
Cobol |
Information |
X |
|
Microsoft SQL server |
Siebel |
Excel |
Record Management |
X |
|
Informix |
Salesforce |
HTTP |
Both direct and |
X |
|
MySQL |
X |
JMS |
X |
X |
|
Teradata |
X |
SOAP |
X |
X |
|
Hadoop |
X |
ODBC |
X |
X |
|
Hewlett-Packard NeoView |
X |
Transporter |
X |
X |
|
IBM Netezza |
X |
IBM |
X |
X |
Table 1
SAP Data Services compatibility
SAP Data Services Target Audience
Several types of users can leverage SAP Data Services, including source system experts, data analysts, developers, and operation managers. The core responsibilities of these roles can be summarized as follows:
- Source system experts – Provide information, metadata about source system and data content, as well as what tables and views to connect through using SAP Data Services
- Data analysts – Translate business requirements into functional requirements and required source data needs. Validate data test results, transformations, and data-cleansing activities.
- SAP Data Services developers – Create technical specs based on input from the data analysts. Responsible for developing all objects, schedules, and test procedures.
- ETL operations’ managers or data architects – Monitor daily processing of ETL jobs, error logs, manual fixes, connectivity, and security. Upgrade and apply SPs and SAP Notes to maintain the overall application. Track key performance indicators (KPIs) for service level agreements (SLAs), system availability, and overall performance. Responsible for maintaining development standards, standard operating procedures (SOPs), naming conventions, Data Dictionary, structured walkthroughs, and approvals. Act as the overall data architect for the SAP Data Services and related systems.
What’s New in SAP Data Services 4.2
With the release of the newest version of SAP Data Services in late 2013, SAP significantly enhanced the prior version to allow for better integration into the SAP BW and SAP HANA environments. Although previous releases enabled you to load data from any source system to these platforms, SAP extended these capabilities to better take advantage of APIs and programs already developed for other SAP applications.
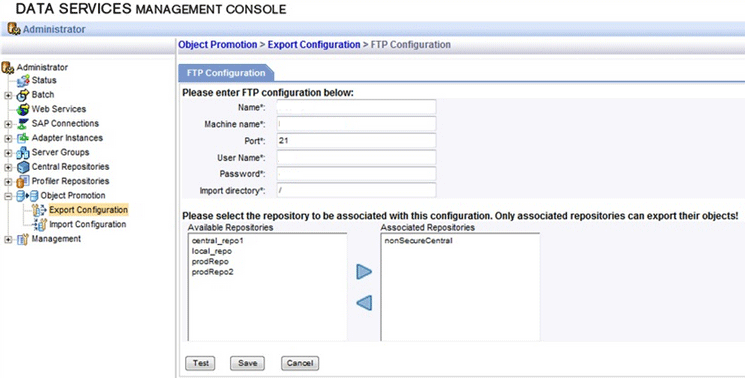
Along with these new features, SAP also provided updates to the new SAP Data Services Management Console (Figure 2). In doing so, it made it easier to locate objects and repositories, and maintain connections to other source systems.
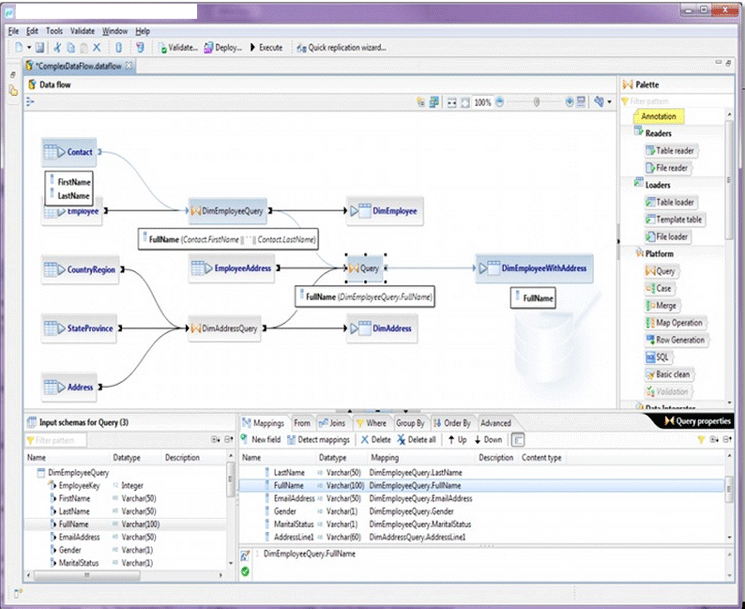
SAP also enhanced the Data Services Workbench (Figure 3), which is where developers maintain most of the data architecture and logical connections. The new capabilities of the workbench include the ability to design data flows. Specifically, you can edit all the data flow architecture within a single comprehensive window with multiple panes that detail the mappings of components such as query transformations. Another new feature is that when a field name is selected, the origin of the field is now shown within the Mappings column. The Project Explorer includes all associated components of a project, including data stores and data flows. You can create folders to enhance organization within Project Explorer. The latest version of the workbench is Eclipse based, meaning that it offers data-visualization options that are similar to the SAP Information Design Tool and SAP HANA studio.
SAP also made changes to SAP Data Services to improve large-scale data loads, which are more common in SAP HANA implementations. In the past, SAP Data Services performed data flows by executing basic SQL statements, and the workload was shared with the SAP Data Services application server. With the new optimization, however, the use of queries to extract data is no longer required. Instead, SAP Data Services can create a calculation view that can retrieve the data and also perform the transformations in memory instead of doing this in the SAP Data Services application. This results in a set of additional benefits:
- Real-time data insight with immediate data profiling
- Push down (i.e., transfer of) data transformations to SAP HANA for more efficient and rapid processing
- Faster loading with parallel data extraction, partitioned data load, and multi-node data load
In addition, with SAP Data Services version 4.2, you can also export and import content from specific repositories. This feature allows you to transport objects between multiple SAP Data Services environments, such as development, testing, and production environments.
SAP Data Services 4.2 also includes capabilities that enable management of SAP Data Services jobs from development to production, such as the management of testing and deployment. In addition, the import/export feature can also be controlled via application security, and it also provides for a comprehensive audit trail that can be used to track the deployment process.
A major benefit of loading data into SAP HANA is that this database provides partition support for column store tables. When tables are partitioned in SAP HANA, SAP Data Services 4.2 uses the partition feature to allow for parallel reading and loading. You can also import SAP HANA partition table metadata for tables partitioned by range that are used for parallel reading and loading. This feature makes it much easier to design and develop data flows and data mapping from any source system directly into SAP HANA. This is because you can now see the SAP HANA table definitions inside SAP Data Services in the File Format Editor screen (as shown in Figure 4). In addition, for a logical partition of SAP HANA tables, list-based range partitions are now supported.

New features of version 4.2 also include enhanced support for spatial data, such as point, line, polygon, collection, or heterogeneous collection inside SAP HANA. This new spatial processing enables you to store, process, and analyze very large amounts of spatially oriented data, such as latitudinal and longitudinal points, in real time, and render them on highly visual geospatial maps. You can visualize data that reveals patterns, relationships, and trends that can be interpreted directly in maps for location intelligence.
Extracting Data by Leveraging SAP Business Suite Extractors
Depending on your system landscape, you should evaluate several factors to determine the optimal solution for extracting data from SAP Business Suite applications. These applications are then loaded into SAP HANA. SAP Business Suite applications include SAP Customer Relationship Management (CRM), Enterprise Asset Management (EAM), Enterprise Resource Planning (ERP), ERP Financials, ERP Human Capital Management (ERP HCM), Product Lifecycle Management (PLM), Supplier Relationship Management (SRM), and Supply Chain Management (SCM).
The needs for such an integrative ETL project may be different from what is required for an SAP BW deployment. Therefore, factors such as table structure and configuration, existing SAP Business Suite extractors, and database Change Data Capture (CDC) capability can all affect the implementation process. Relevant variables include table structure and configuration, delta extraction mechanisms, and whether the tables only permit insertion, update permissions, and timestamps. I discuss these variables later. I explore two of the most common implementation options: the ABAP Application Layer and Direct Relational Database Management System (RDBMS) Connection.
Implementation of the ABAP Application Layer
SAP recommends and supports the ABAP Application Layer approach for extracting data from SAP Business Suite tables. In this case, data can be extracted either directly from the tables or through the use of content extractors. When SAP Data Services connects to tables through the ABAP Application Layer, there are certain types of tables that you can access in SAP Business Suite systems. These include cluster, pooled, and transparent tables. Cluster and pooled tables are defined as being logical since they can combine at least two physical tables to ensure data persistence. The logical tables simplify the process of handling the cumbersome physical tables, which is one reason why it is the recommended approach.
Beyond defining the tables as either cluster, pooled, or transparent, SAP Data Services also classifies these tables as either being insert only or updatable. Insert-only tables solely permit new records (inserts). The Change Data Capture (CDC) solutions that can be used for insert-only tables include:
- Full refresh – Do not use with tables containing an abundance of rows due to performance implications
- Timestamp-based CDC – This is meant for cases in which the tables targeted for data extraction do not already have a creation timestamp configured. An alternative option to using insert-only tables is to implement the primary key in place of the creation timestamp, but this is only possible if the primary key is in sequential format.
- Target-based CDC – Do not use with tables containing an abundance of rows due to performance implications
Conversely, updatable tables permit inserts and updates. The CDC options for updatable tables are the same, but involve some nuanced differences in the steps and capabilities:
- Full refresh – Do not use with tables containing an abundance of rows due to performance implications
- Timestamp-based CDC – This is meant for cases in which the tables targeted for data extraction do not already have a creation timestamp configured. If the source data is modified while the SAP Data Services job is running, it is possible for the delta process to be affected, which results in certain changes being skipped. The SAP Data Services Designer Guide offers resolutions to this potential pitfall.
- Target-based CDC – Do not use for tables containing an abundance of rows due to performance implications
Extractors: What Are They and How Are They Used?
Having a clearly defined understanding of the associated logic and output of an extractor is a prerequisite to using it. Specifically, extractor data may be modified by SAP BW for reporting, and this produces logical records. These records are not accessible if the extractor used in SAP Data Services is used to load data into SAP HANA. Thus, caution should be exercised when deciding which extractor to use. See SAP Notes 1521883 and 1585204 for guidelines regarding extractor prerequisites and implementations.
The advantages of using Business Content extractors versus ABAP data flows include:
- Simple job deployment and upkeep. Data is not staged in files, rather it is streaming and no ABAP programs are involved.
- The same recommended and supported connection to ERP is the same as what SAP BW has used all along
- Delta loads are completely supported
Prerequisites for native access to SAP Business Suite with SAP Data Services can be found in SAP Note 1522554 (SAP NetWeaver BW Support Package requirement for Data Services SAP extractor support). SAP Business Suite Content Extractors are objects that are available as of SAP Data Services 4.x. The two options for implementing the extractors are either with or without the ODP interface. SAP extractors can be used in the same way as a data flow would be used for a typical data source, such as third-party data sources (Figure 5). Extractors can be observed and imported from an SAP application DataStore.

An ODP outlines a group of data interfaces that classify data as either transactional or master (attributes, hierarchies). These data interfaces make the data accessible for analytics and mass replication. This accessibility is enabled by the capabilities of delta queues. The delta queues facilitate the segregation of the recipients from the extractor, thus permitting the use of several sources. There are assets and constraints to choosing an approach with or without an ODP. Some of these are as follows:
- Pros of ODP-enabled extractors – Delta capabilities of supported extractors. Native to an SAP Data Services data flow, so no ABAP data flow is necessary to directly access data from SAP Data Services.
- Constraints of ODP-enabled extractors – Limited to use with extractors that have been officially released, and these are a division of the SAP Business Suite system extractors. See SAP Note 1558737 for details regarding which data sources have been released for the ODP data replication API. Master data hierarchies (HIER) extractors are not supported.
- Pros of non-ODP-enabled extractors – Compatible with transactional data and master data attributes. Compatible with all versions of SAP ERP
- Constraints of non-ODP-enabled extractors – Master data text and hierarchies are not supported. ABAP data flows are required. No delta capability, so only complete data extracts are possible.
There are three options for using CDC with extractors:
1. Full refresh
- SAP does not recommend this option for tables containing an abundance of rows due to performance implications
- Simple to deploy and administer. Involves deletion of all records within the target table, and then loading the table with all records captured by the extractor. This certifies that no data is omitted due to human error. A complete dataset can be returned by all extractors, so the use of full refresh is an option.
2. Source-based CDC
- Only rows that have been modified are extracted from the source
- This approach is recommended due to enhancements to performance by minimizing the number of rows that are extracted. The Delta_Enable attribute within the extractor properties indicates whether it is configured for delta capture.
3. Target-based CDC
- Do not use for tables containing an abundance of rows due to performance implications
- All data is extracted from the source system and reconciled with the target system. Once complete, the comparison highlights the rows that are flagged as Delete, Insert, or Update. The Table_Comparison transform is consumed to use this option within SAP Data Services.
- If the target table contains a primary key, the columns should suffice to indicate whether a row from the source system is marked as Insert or Update in the target
- If there are other fields besides the primary key that offer distinction, they can be defined as Compare Columns to augment performance
Direct RDBMS Connection
This Direct RDBMS Connection approach is ideal for users who are proficient with SAP Data Services. Despite being a simple process, directly extracting data from SAP Business Suite tables presents restrictions since it is not compatible with pooled or cluster tables, such as BSEC (One-time account data document segment) or BSED (Bill of Exchange Fields Document Segment). The vendor licensing could also be a constraint in terms of direct RDBMS access. As a result, SAP does not support this method, and it is not a popular choice. If the aforementioned limitations are not a deterrent, then the optimal approach is to use the application layer to directly extract SAP Business Suite data rather than forming a connection to the RDBMS on the back end. The following options are available:
1. Full refresh
- SAP does not recommend this option for tables containing an abundance of rows due to performance implications
- Simple to deploy and administer. Involves deletion of all records within the target table and then loading the table with all records captured by the extractor. This certifies that no data is omitted due to human error.
2. Source-based CDC
- Only rows that have been modified are extracted from the source
- This approach is recommended due to enhancements to performance by minimizing the number of rows that are extracted
3. RDBMS-based CDC
- This is an option offered by certain RDBMS vendors, including Oracle and Microsoft. In this case, the RDBMS inserts the modified data to internally replicated tables.
- The modifications are recorded and can then be used by SAP Data Services to load deltas
- SAP Data Services enables access to source-based CDC data from Oracle and Microsoft for extraction from the SAP Business Suite RDBMS. See vendor guides for details regarding RDBMS-based CDC.
4. Timestamp-based CDC
- This can only be used if the RDBMS is not a Microsoft SQL server or Oracle server (before version 9i)
- There are several options for how to implement a timestamp-based CDC solution, depending on which timestamps are offered in the source tables
- If the source data is modified while the SAP Data Services job is running, it is possible for the delta process to be affected, which would result in certain changes being skipped. The SAP Data Services Designer Guide offers resolutions to this potential pitfall.
5. Target-based CDC
- Do not use for tables containing an abundance of rows due to performance implications
- All data is extracted from the source system and reconciled with the target system. Once complete, the comparison highlights the rows that are flagged as Delete, Insert, or Update. The Table_Comparison transform is consumed to use this option within SAP Data Services.
- If the target table contains a primary key, the columns should suffice to indicate whether a row from the source system is marked as Insert or Update in the target
- If there are other fields besides the primary key that offer distinction, they can be defined as Compare Columns to augment performance
An Alternative to SAP Data Services: Direct Extractor Connection (DXC) for Data Replication to SAP HANA
The DXC option offers a transparent method for batch data replication from SAP Data Source extractors (ERP) that already exist for import into SAP HANA. DXC became generally available as of SAP HANA SP4. This scenario is typically suited for SAP HANA standalone (data-mart) implementations and does not involve SAP Data Services or SAP BW on SAP HANA. There are numerous advantages to using the DXC approach for data provisioning, specifically:
- Pre-existing SAP Business Suite foundational models are available in SAP HANA data mart deployments. They accelerate SAP HANA implementations and streamline data-modeling tasks in SAP HANA.
- This is a straightforward option that minimizes total cost of ownership (TCO). No supplementary system hardware (application or server) is required for the landscape. It involves a proprietary ETL mechanism that already exists in SAP Business Suite system and an HTTP(S) connection to SAP HANA.
- It offers CDC or delta capability. This presents a comprehensive mechanism that is tailored for all delta-processing varieties. It provides improved efficiency since only new or modified data is imported into SAP HANA.
- It offers an avenue for a semantic data between the SAP Business Suite and SAP HANA. Numerous extractors contain application logic that offers data clarity. It provides assurance of data quality by accurately signifying ERP business content.