/HANA
Now that a majority of the core SAP Business Suite applications have been enhanced to run on SAP HANA technology, many ABAP developers are left wondering how this transition might affect them in the future. See how SAP HANA technology is integrated and used in systems using the SAP Business Suite.
Key Concept
Running the SAP Business Suite on SAP HANA allows you to use in-memory capabilities to increase the speed with which you process and analyze SAP transactional data in real time.
With all the hype surrounding SAP HANA technology, wrapping your head around what HANA is and how it fits into the overall SAP development landscape can be difficult. On one end of the spectrum, you have those who dismiss HANA as just another database. On the other end, you have those who claim that HANA marks the end of ABAP programming as we know it. As is the case with most things in life, the truth lies somewhere in the middle.
For developers working in the analytics space, many of these myths have been dispelled now that developers have had an opportunity to gets hands-on experience with the various HANA-based product offerings and see how HANA technology works. However, for ABAP developers working on applications in the SAP Business Suite (e.g., SAP ERP Central Component [SAP ECC]), there’s a lot of uncertainty. I’ll provide clarity in this area by illustrating how HANA technology is integrated into the SAP Business Suite.
Basic Concepts
Since the term HANA can take on different meanings depending on the context, I’ll start by explaining what HANA is from an SAP Business Suite perspective. Here, HANA primarily plays the role of the system database. In this regard, the HANA database is positioned much like some of the more popular database systems that you might be accustomed to working with in the SAP landscape: Oracle, Microsoft SQL Server, and so on. Compared with these other leading products, though, there are several aspects of the HANA database architecture that set it apart:
- Use of in-memory technology: HANA is classified as an in-memory database. This means that all the data is accessible via main memory, allowing the database kernel to access the data directly instead of having to incur the latency associated with disk-based accesses.
- Support for column-oriented storage: Unlike most competing RDBMSes, which store table data using a row-oriented approach, HANA prefers to store table data using a column-oriented approach. Figure 1 illustrates the differences between the two approaches. Imagine you’re running a SQL query with a WHERE clause that contains a filter on column A. With the row-oriented approach, a comparison on column A requires that the database kernel scan through quite a bit of irrelevant data to find entries that match the condition in the WHERE clause. Conversely, with the column-oriented approach, the scan process is highly optimized since the kernel can perform a range scan across a set of contiguous memory blocks.
- Support for massive parallelization: One of the by-products of the column-oriented approach to table storage is that it allows certain low-level database operations to be organized into parallel tasks. Wherever possible HANA exploits these opportunities, distributing query processing across available CPU cores. Add in built-in compression on column data, and you end up with a lot of CPU cores processing pieces of a query in parallel, working on their own little chunk of localized data.
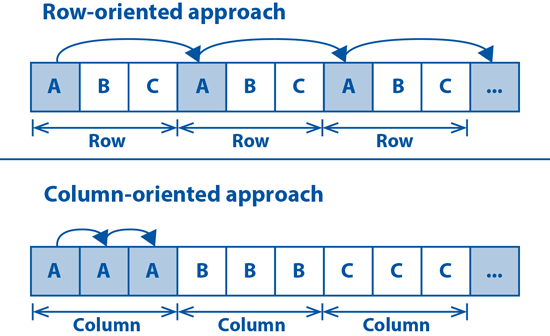
Figure 1
Differences in a column-oriented approach to table storage
Collectively, these features make it possible for HANA to access large amounts of data in real time. This opens the door to all kinds of interesting possibilities. Before, processes requiring large amounts of data were relegated to batch processing of one form or another. Here, background jobs might run for days at a time, crunching through mounds of data to build materialized views (or summary tables) that could be accessed for reporting. Besides being complicated, a major problem with this approach from an end-user perspective is that you’re almost always working with data that is outdated. Even the delta-load functionality built into data warehousing tools such as SAP NetWeaver BW can only help so much in this regard.
With HANA, though, it’s a different story. Because the HANA database can churn through significant volumes of data in real time, you no longer have to worry about building materialized views, for example. Instead, you simply craft the appropriate SQL statements and let the database do all the hard work. This is, after all, what database systems were designed for in the first place.
Note
Because I’m talking more about the effect of HANA on online transaction processing (OLTP) systems such as the ones found in the SAP Business Suite, I won’t digress into a discussion about whether HANA marks the end of the conventional split between OLTP and online analytical processing (OLAP) systems. Suffice it to say that HANA makes it possible to process large volumes of data in an OLTP system without bringing the system to its knees. This allows you to reconsider how you design certain applications with heavy data requirements.
How Do I Access HANA from ABAP?
Because HANA is so radically different from most traditional RDBMSes, many developers often wonder how to interface with it from an ABAP context. The short answer is that you can interface with it using Open SQL statements in ABAP as you normally would. Figure 2 illustrates the layers of abstraction that make this possible. Here, the database interface (DBI) component converts Open SQL statements into standard SQL, which is funneled through the database-specific library (DBSL) to the HANA database query processor engine.
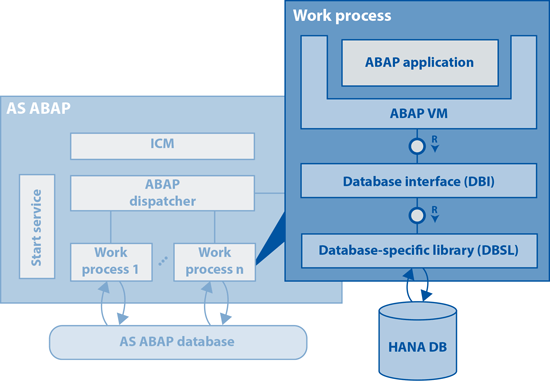
Figure 2
Architecture of an AS ABAP work process
Because the HANA database is fully SQL compatible, you can construct queries and data manipulation (DML) statements just as you would for any normal database. You don’t have to worry about converting between native data types or using some kind of proprietary query syntax. You hand your Open SQL statements off to the DBI and let it do its thing.
Although Open SQL-based access covers the majority of access scenarios you face in day-to-day development tasks, it’s not the only game in town. If you want to tap into some of the more advanced (and proprietary) features of the HANA database, you can use the ABAP Database Connectivity (ADBC) library to build native SQL queries or access stored procedures. If you’re not familiar with stored procedures, think of them as being like Business Application Programming Interfaces (BAPIs) that reside in the database layer. Here, you can supplement data accesses with imperative logic that performs validations, calculations, and so forth.
In addition to the traditional SQL-based access options, HANA provides a unique way of accessing the data. With the addition of the SAP HANA Extended Application Services (SAP HANA XS), it is also possible to expose data models using representational state transfer (REST)- or OData-based services. Here, clients of all kinds can access the data using the HTTP(s) protocol without having to install a database library. This scenario is strictly optional, but does open the door to many interesting application possibilities — particularly in the mobile application space with SAP UI5.
Do I Have to Learn New Programming Languages to Use HANA?
Another common question floating among ABAP developers is whether the use of HANA technology requires them to learn new programming languages. The answer is yes and no. As I noted earlier, it is certainly possible to access HANA data from ABAP using Open SQL statements. However, if you want to get the most out of what HANA has to offer, you may have to go beyond basic SQL and tap into some of the proprietary features built into HANA. This requires that you learn how to program stored procedures in a proprietary language called SQL Script. This language has a similar feel to Oracle’s PL/SQL, providing procedural extensions on top of SQL that make it possible to push more program logic down to the database layer.
Another language you may hear thrown about in the HANA space is server-side JavaScript. This language is the server-side counterpart to the client-side scripting language used in Web application development. Within the aforementioned SAP HANA XS, server-side JavaScript is used to build lightweight, reusable services — mostly of the OData variety. Again, use of this technology is strictly optional, so rest assured that server-side JavaScript is not going to replace ABAP anytime soon. Still, as HANA technology matures, it’s increasingly likely that you’ll brush up against some JavaScript at some point soon.
Where Do We Go from Here?
The main role of HANA technology in SAP Business Suite systems is to provide the system database. Because this integration is mostly seamless from the perspective of the AS ABAP, ABAP developers will hardly notice the difference whenever the initial transition takes place. However, just because you don’t get any syntax errors doesn’t mean that you’re using HANA technology correctly. To get the most out of what HANA has to offer, you need to change the way that you view the database from an application design perspective. This can be difficult to conceptualize at first because the HANA approach goes against around 30 years of conventional thinking.
For years, ABAP developers have been taught to do all our heavy data crunching outside of the database. This mind-set came about not because it was the best way of designing applications, but rather out of necessity because the database layer has not scaled very well in large SAP Business Suite systems. Since HANA technology eliminates these barriers, you need to reevaluate the ways that you design applications. Whereas before you might have shied away from using complex SQL joins for fear of causing a database bottleneck, now you can use the capabilities of the database as much as possible because that’s what it’s designed for.
As a result, you need to brush up on your SQL skills, because you’re about to see a major shift back to a data-centric approach to enterprise application development.

James Wood
James Wood is the founder and principal consultant of Bowdark Consulting, Inc., an SAP NetWeaver consulting and training organization. With more than 10 years of experience as a software engineer, James specializes in custom development in the areas of ABAP Objects, Java/J2EE, SAP NetWeaver Process Integration, and SAP NetWeaver Portal. Before starting Bowdark Consulting, Inc. in 2006, James was an SAP NetWeaver consultant for SAP America, Inc., and IBM Corporation, where he was involved in multiple SAP implementations. He holds a master’s degree in software engineering from Texas Tech University. He is also the author of Object-Oriented Programming with ABAP Objects (SAP PRESS, 2009), ABAP Cookbook (SAP PRESS, 2010), and SAP NetWeaver Process Integration: A Developer’s Guide (Bowdark Press, 2011). James is also a contributor to Advancing Your ABAP Skills, an anthology that holds a collection of articles recently published in SAP Professional Journal and BI Expert.
You may contact the author at jwood@bowdark.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




