This is the first article in a mini-series covering advancements in the ABAP language in its 7.40 release. It gives an introduction to inline declarations, type inference, and constructor expressions; concepts which can significantly improve the conciseness of your ABAP code.
Key Concept
ABAP, the programming language of the SAP Business Suite, has gone through a long evolution. Despite certain advantages, like its tight server integration and powerful internal tables, it has always been clumsy on the simple tasks, like computing a value of structured type, due to its lack of expression support. This is being addressed by the latest extensions.
With the emergence of SAP HANA, innovation in the ABAP Server has regained momentum. Its 7.40 release, which underlies the renewed Business Suite (now S/4HANA), has already gone through several sub-releases since 2013. This is the first article in a mini-series covering advancements in the ABAP language in 7.40.
Note
At the time of this writing, the most recent 7.40 Support Package (SP)
bundled with a kernel release is SP8. If you are working with an earlier
ABAP kernel (SP 2 or 5), some features described in this article may
not yet be available, or only with restrictions.
The main topics are inline declarations, type inference, and constructor expressions. A follow-up article will investigate table selection, table comprehensions, reduction, grouping, and more. As always, a good starting point to get an in-depth look at new ABAP features is the “Release Specific Changes” section in Horst Keller’s excellent online documentation (https://help.sap.com/abapdocu_740/en/index.htm?file=abennews-740.htm ). In the present article, I try to add some extra value, such as historical background, motivation, and rationale for why things are as they are, as well as practical hints.
This ABAP release doesn’t bring a new overarching paradigm or “programming model” (perish the thought). All extensions are about the microcosm of programming, such as avoiding redundancy and achieving elegance in the computation of (structured) data. Once adopted, the new features will have a tendency to show up in almost every other line of your code.
If you are an “ABAP dinosaur” in your company, the new, smoother ABAP appearance could help to grow your confidence towards your freshman colleagues with their hipster languages…. On the other hand, if you are one of those, you may now find it less painful – perhaps even convenient – to build a piece of ABAP functionality.
Ancient Past – Recent Past – 7.40
“ABAP is a fourth-generation language designed specifically for the purpose of high-level business programming. Therefore, it does not allow you to write
IF x > n * 2.
n = f( n + 1 ).
x = n.
but requires:
DATA: n2 TYPE I, n1 TYPE i.
COMPUTE n2 = n * 2.
IF x > n2.
COMPUTE n1 = n + 1.
CALL METHOD f EXPORTING p = n1 RECEIVING r = n.
MOVE n TO x.
The mandatory use of variables for intermediate results and the resemblance to plain English sentences lead to safe and understandable programs.”
If you can’t quite follow this line of thought, you are not alone.
The first thing to note is that there is no such thing as a business programming language, nor are there special demands for such a kind. When we say “business” at SAP in the context of programming, you may implicitly translate that to “semantic” (concerning the subject that a piece of software deals with). Like any general-purpose language, ABAP should make it as easy as possible to express the intended semantics. (Well, other connotations we have here at SAP with “business” are that the software is typically huge, does a serious job, handles mass data, and runs very stably. All true for ABAP, but these are not exclusive business attributes.)
Secondly, the verbose syntax of ill COBOL fame sacrifices compactness and orthogonality for a pseudo-natural appearance. A well-chosen set of concise symbols is easier to memorize and doesn’t drown the meaning in a sea of words. Here is a pair of ABAP keywords (borrowed directly from COBOL) whose useless redundancy is emblematic:
MOVE x TO n.
COMPUTE n = x + 1.
There is no relevant difference between these statements—both are assignments of a right-hand-side (RHS) expression to a left-hand-side (LHS) variable. Furthermore, there is no justification to limit real expressions (i.e., consisting of more than one field) to a special statement COMPUTE. They should be allowed in every R-value position of the grammar (i.e., wherever a value is read). Being forced to use helper variables even for trivial situations is a nuisance. Finally, a grown-up language will also adopt the concept of L-values (expressions that yield a location to which another value can be assigned).
In the 7.02 release, ABAP took a first big step, allowing computation to occur directly in comparisons, method arguments (as in the example above), and many other R-value positions. String expressions were introduced, as well as nested and chained calls.
In the 7.40 release, even more statements have been expression-enabled. More importantly, a full set of operations now exists to handle any kind of value in the type system of ABAP (atomic, structure, table, and reference). If you care to look, the documentation referenced earlier now rates MOVE and COMPUTE as obsolete.
Pure Convenience: Inline Declarations and Type Inference
Before diving into the new expressions, it’s useful to familiarize yourself with another concept, which is related, but somehow more fundamental.
How often have you had the problem that you want to call a method and need variables to which to bind its EXPORTING or RETURNING parameters? Do you use code completion to retrieve the needed types? Or perhaps you navigate to the declaration, copy the type names, and paste them into the calling code? The question is: Why should you have to bother? The ABAP compiler knows the method (else it would complain) and hence the types, which it uses to check compatibility. However, a compiler’s job is not just to supervise you, it should support you. In particular, it should help to eliminate redundancy.
This is the rationale behind the concept of inline declaration: You just specify the intent to declare a new variable and bind it to a value. Then the compiler determines the required type from the context, such as a method signature. This is called type inference. Compared to some other languages (especially functional), its power is limited, but usually sufficient. A typical example using a meaningful variable name is shown in Figure 1. The code completer has the same capability as the compiler, so it can tell you what type you got for the variable. (If it is a reference and you type –>, or a structure and you type –, of course it also offers the components for completion.)

Figure 1
Code completion knows the type of an inline-declared variable
So the syntax DATA(x) gives you a variable named x. In other places, the syntax FIELD-SYMBOL(<x>) gives you a field symbol (the ABAP flavor of a pointer) named <x>. The most prominent example is in the loop:
LOOP AT itab ASSIGNING FIELD-SYMBOL(<line>).
… <line>-comp = <line>-comp + 1. …
ENDLOOP.
No blank spaces around the parentheses, please. (Lexically, these keywords are relatives of the (blank-less) "VALUE(x)" in a parameter declaration.)
As a rule of thumb, an ABAP grammar position is enabled for inline declaration if it is an L-Value that is written to but not read from. So, you can inline declare after IMPORTING in a method call, but not after CHANGING. Exceptions to the rule are peripheral and deprecated ABAP areas (e.g., datasets or lists), which are neither expression nor declaration enabled. Multiple bindings in one statement are possible:
meth( IMPORTING p1 = DATA(x)
p2 = DATA(y)
RECEIVING p3 = DATA(z) ).
Incidentally, this demonstrates another extension: Methods can now have RETURNING parameters along with EXPORTING and/or CHANGING parameters. (Disallowing this combination never really made sense. Since you are in an imperative language, any method can have side effects, even if it’s called functional. Explicit CHANGING parameters are just truthful about it. Explicit EXPORTING parameters compensate for the absence of tuple results.)
However, attempting to move DATA(z) to the LHS results in a syntax error (Figure 2). Why? Because now it’s no longer a method-call statement, but an assignment with a RHS method-call expression; and declarations in the middle of an expression are forbidden for hygienic reasons. (Consider IF 0 = 1 AND meth( IMPORTING p = DATA(x) ) = 2. The part after AND is never evaluated, so conceptually you’d have an unbound variable.)

Figure 2
Inline declaration inside expressions is forbidden
More About Inference Rules, Some Pitfalls, and Style
Table 1 is a collection of more working inline declarations. For example, all internal-table statements giving access to a table line can be used with ASSIGNING FIELD-SYMBOL(<x>), INTO DATA(x), and REFERENCE INTO DATA(x).
| Inline declaration |
Inferred type
|
|
| DATA(x) = y. |
Type of y
|
|
| DATA(x) = 'abcd'. |
C(4) |
|
| DATA(x) = y && '~'. |
STRING |
|
READ TABLE itab INDEX 1
REFERENCE INTO DATA(x). |
REF TO line-type of itab |
|
| ASSIGN 100 TO FIELD-SYMBOL(<x>). |
I
|
|
| ASSIGN lcl=>(a) TO FIELD-SYMBOL(<x>). |
DATA (generic)
|
|
CATCH cx INTO DATA(x).
|
REF To cx
|
|
FIND ALL OCCURRENCES OF a IN b
MATCH COUNT DATA(x) RESULTS DATA(y).
|
x : I, y : MATCH_RESULT_TAB
|
|
SPLIT blob AT null INTO TABLE DATA(x)
IN BYTE MODE.
|
STANDARD TABLE OF XSTRING
|
|
GET TIME STAMP FIELD DATA(x).
|
TIMESTAMP
|
|
CONVERT TIME STAMP a TIME ZONE b
INTO DATE DATA(x) TIME DATA(y).
|
x : D, y : T
|
|
SELECT … INTO TABLE @DATA(x).
|
Suitable type. (7.40 Open SQL extensions warrant an article of their own. . .[more on this in an upcoming article])
|
|
Table 1
Examples of inline declarations
An interesting case is arithmetic, as in:
DATA(x) = 1 + y * f( z ).
Here, the compiler infers the calculation type of the RHS, which is the strongest numeric type of all involved operands (in ascending order: I, P, F, and DECFLOAT34).
An inline declaration may fail because no concrete type information can be derived from the context. In Figure 3, the compiler has no idea what type to use for x, as the formal parameter (ironically named DATA) is just a STANDARD TABLE.

Figure 3
Compiler complaining about too-generic type
However, the inference rules are designed to work whenever reasonably possible. For example, if an EXPORTING parameter has the generic type CSEQUENCE, an inline declaration bound to it gets the type STRING. So if you have a method with a parameter of concrete type (e.g. C(20) or STRING) and later you generalize it (e.g., to CSEQUENCE), then existing calls to the method with inline declarations for this parameter will not break (with a syntax error as in Figure 3). Although full generalization safety of signatures is not guaranteed, it is desirable to approximate it. Full safety would mean that method calls could never get syntax errors when a parameter of the called method is changed to have a more generic type than it had before. See more on this in the section on CONV.)
For constant RHS value, one might think that inline declaration is the same as initialization, but it isn’t. Consider this fragment:
DO n TIMES.
DATA x TYPE i VALUE 1.
DATA(y) = 1.
Variable x is initialized to 1 only once upon procedure entry, but y is (re-)set to 1 in every iteration. The first statement is purely declarative. The second is operational (an assignment statement). If you want only initialization, prefer the first form because it saves the run time for an assignment.
Another expectable misconception is that inline-declared variables have a local scope. Unfortunately, they don’t. (No doubt it would be better if they were locally scoped. But this is one of the concepts that the ABAP machine is rather reluctant to learn.) Like a normal DATA or FIELD-SYMBOLS declaration, an inline-declared variable is visible all the way down to the end of the procedure. You’ll typically notice that in situations such as Figure 4.
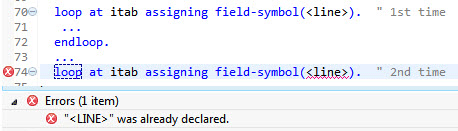
Figure 4
Inline-declared variable still in scope
Notwithstanding this weakness, it is obvious that an old ABAP guideline must be reconsidered: to declare all variables at the top of a procedure. On the contrary, inline declarations encourage you to declare a variable where you need it. Static single assignment (SSA) is a respectable pattern:
data(ixml) = cl_ixml=>create( ).
data(strf) = ixml->create_stream_factory( ).
data(istr) = strf->create_istream_string( s ).
data(docm) = ixml->create_document( ).
ixml->create_parser( document = docm istream = istr )->parse( ).
The all-at-the-top guideline was motivated mainly by the dynamic ASSIGN allowing you to see a variable before its static declaration—not a convincing reason to rip apart related information.
It’s a good idea to use declarations as if they were subject to block scope: Avoid re-use of a variable declared inside a compound statement, like IF or LOOP, after the end of that statement. Be tidier than the compiler forces you to be.
Constructor Expressions: Something NEW
CREATE OBJECT obj EXPORTING p = 1.
Why is this a statement? Maybe to give you the notion of actively manipulating the heap of the ABAP engine. Well, of course you are, but that’s nothing you should think about. And why do you have to bind the created object to a variable if, for example, you just want to pass it to a method, or insert it into a table?
The answer is, of course, that object creation should be an operation onthe expression level and be separate from variable binding. For a number of related questions, we will arrive at a similar answer. This warrants a common meta syntax for these new kinds of expression (Figure 5).

Figure 5
Common pattern of constructor expressions (a) with explicit type (b) with type inference
For object creation, the constructor operator is NEW, the type name is a class name, and the inner syntax is a list of parameter bindings for the constructor method:
obj = NEW myclass( p1 = 'a' p2 = x + 10 ).
Since there is an LHS variable, you can omit the class name and leave it to the compiler’s type inference, indicated by the “type placeholder” #:
obj = NEW #( p1 = 'a' p2 = x + 10 ).
On the other hand, if the object variable is being introduced right here, you can omit its declaration, explicitly name the desired type, and let type inference work from right to left:
DATA(obj) = NEW myclass( p1 = 'a' p2 = x + 10 ).
Or, if you don’t need the reference afterwards and the type is clear from the context:
do_with_myobj( NEW #( p1 = 'a' p2 = x + 10 ) ).
The examples below often use # when the type is irrelevant for the discussion, assuming it can be inferred.
NEW also serves for the creation of (non-object oriented [OO]) data objects. Suppose you need to create a structure-typed value on the heap. Previously you would write:
CREATE DATA struc_ref.
struc_ref->c1 = 'a'.
struc_ref->c2 = x + 10.
Now it’s simply:
struc_ref = NEW #( c1 = 'a' c2 = x + 10 ).
So here the inner syntax consists of bindings for (some or all of) the structure type’s components. If there is no concrete type from the context, use an explicit type name instead of #. For example, if the target variable has the generic type REF TO DATA:
data_ref = NEW t_struc( c1 = 'a' c2 = x + 10 ).
Previously, this was even harder to achieve; it required an auxiliary variable or field symbol.
When using #, there is no mention of the instantiated type. In fact, a where-used search for t_struc will not return the following line, which creates an initial structure value and passes a reference to it to a method:
do_with_struc_ref( NEW #( ) ).
Think of it this way: If you rename the type, this is not a position you have to adjust. Only if you supply components of the structure:
do_with_struc_ref( NEW #( c1 = 'a' c2 = x + 10 ) ).
do you get findings of c1 and c2. These will need adjustment in case of component renaming. Analogously, the finding you get for
do_with_myobj( NEW #( p1 = 1 p2 = x ) ).
located at NEW is not the class, but its constructor method. A signature change there may require adaptation.
So, avoidance of temporary variables and use of type inference (#) in combination makes code more tolerant to change. In the ideal case, types (e.g., in a method signature) can be changed without having to adapt any point of use.
Let’s just mention briefly that the other ABAP statement for obtaining a reference,
GET REFERENCE OF struc INTO ref_struc.
arrives in the 21st century as
ref_struc = REF #( struc ).
C programmers in the audience may associate “&struc”.
Finally, the equivalent of the "?=" assignment is the CAST operator. Like NEW, it allows chaining, i.e., continuing with a method call or (as here) attribute access:
DATA(comps) = CAST cl_abap_structdescr(
cl_abap_typedescr=>describe_by_data( x ) )->components.
Furthermore, NEW and CAST are special in that they are the first ABAP expressions to be LHS-enabled—they yield L-values when chained with "->":
CAST t_struc( data_ref )->c1 = 'a'.
NEW my_class( )->attr = 10.
The second line makes sense (only) under the assumption that the constructor stores the object somewhere else, so that it outlives the statement.
Another popular use case for NEW with chaining is object creation for one-off actions:
NEW my_class( )->do_something( )->do_something_else( ).
No need to declare an object variable for this.
Adding VALUE to Structures and Tables
I started our tour of constructor expressions with NEW, but a seasoned ABAP developer knows that heap objects are not the leading concept in ABAP. Structures and internal tables are central as data containers. In that light, it’s hard to believe that ABAP never had a decent way of expressing values of these types.
The solution for structures is already clear from the discussion of NEW. You just need an operator that creates values in place rather than on the heap. It’s called VALUE:
struc = VALUE #( c1 = 'a' c2 = x + 10 ).
Unbound components remain initial. So, if a method has a parameter that isn’t optional, but you don’t have anything to pass, you can pass the initial value of the required type like this:
do_something( … p = VALUE #( ) … ).
This syntax works for all types, not just structures.
By the way, the arithmetic in the examples is just there to remind you that (of course) all these operands can be arbitrary expressions. Indeed, for deep structures, it’s perfectly okay to have nested VALUE operators:
VALUE #( … sub = VALUE #( c1 = 'a' c2 = x + 10 ) … )
Alternatively, you can write:
VALUE #( … sub-c1 = 'a' sub-c2 = x +10 ) )
However, the compiler makes sure there are no overlaps (Figure 6).

Figure 6
Compiler detects overlapping component specifications
If you don’t want to create a structure value from scratch, but from an existing value, you need the BASE addition (also available with the NEW operator, though I didn’t mention it there):
struc1 = VALUE #( BASE struc c1 = 'a' ).
The BASE operand is also an R-value, so it can be, for example, a method call. Even if it is a variable, like struc, it is left unchanged by the operation. Imagine that its value is copied to an invisible auxiliary variable and then component c1 is changed. The more components the structure has, the greater is the efficiency gain over a list “… c2 = struc-c2 c3 = struc-c3 …”.
In fact, an “invisible auxiliary variable” is exactly what the compiler uses internally. What it also does is to clean up this variable after use—something programmers usually don’t care about. This internal CLEAR causes a tiny run-time overhead, for the sake of better memory behavior.
VALUE generalizes to table types—more precisely, internal tables with a fixed number of lines. (How to build table values with a variable number of lines will be covered in my follow-up article, under table comprehension.) Sad to say, there are probably thousands of macro definitions out there with content like this:
tmp-c1 = &1.
tmp-c2 = &2. …
APPEND tmp TO tab.
only to facilitate filling lines into a table. From now on, to build an internal table with lines of the above structure type, simply write:
structab = VALUE #( ( c1 = 'a' c2 = x + 10 )
( c1 = 'b' c2 = x + 20 ) … ).
Thus, each line specification is enclosed in an inner pair of parentheses. Unstructured line types work without component names:
inttab = VALUE #( ( x - 10 ) ( x ) ( x + 10 ) ).
A component value shared by several lines can be lifted to the outer parentheses, which is especially useful if it involves a computation. The following expression results in a table with five lines: [(c1=f(x), c2=10), (c1=f(x), c2=20), (c1=f(x), c2=30), (c1=f(y), c2=40), (c1=f(x), c2=50)]
VALUE #( c1 = f( x )
( c2 = 10 ) ( c2 = 20 ) ( c2 = 30 )
c1 = f( y )
( c2 = 40 ) ( c2 = 50 ) )
Finally, lines of another table (all or some) can be included as well:
VALUE #( ( 10 ) ( 20 )
( LINES OF inttab1 )
( LINES OF inttab2 FROM idx_lo TO idx_hi ) ).
Sometimes there are several ways to achieve the same result:
VALUE #( ( LINES OF tab1 ) ( LINES OF tab2 ) ) º
VALUE #( BASE tab1 ( LINES OF tab2 ) )
This corresponds to equivalent sequences “clear; insert lines; insert lines” vs. “move; insert lines” on the result variable. In case you just want to insert another line into a table, the most evident form (with type inference, of course) is:
INSERT VALUE #( c1 = … c2 = … ) INTO TABLE structab.
Be very careful with assignments of the form “x = VALUE #( … x … )” (the same x on the left and on the right). In order to not waste time on possibly expensive constructions of intermediate values, ABAP builds the result value directly in x, intermediate states of which are therefore “observable” in the RHS expression. Quiz: If tab initially contains one line, what is its content after the first and second statement?
tab = value #( base tab ( lines of tab ) ( lines of tab ) ).
tab = value #( ( lines of tab ) ( lines of tab ) ).
(Answer to quiz: After the first assignment: Four lines [second LINES OF clause “sees” the result of the previous duplication]. After the second assignment: empty [without BASE, the table is cleared first].)
Here we clearly sacrifice some cleanliness (the technical term is referential transparency) on the altar of performance.
CONVersions and CONDitions
ABAP goes to the limits of sanity to define conversion rules for almost any pair of types, but unfortunately doesn’t apply them for parameter passing. (Doing necessary conversions implicitly is a service called coercion in languages that offer it.)
If you have a STRING parameter, you can’t pass a type C(10) value. Instead you have to:
DATA tmp TYPE string.
tmp = c10.
do_with_string( tmp ).
The CONV operator does away with this nuisance; it offers the complete conversion rulebook (aka the MOVE statement) on the expression level:
do_with_string( CONV #( c10 ) ).
In an inline declaration, it can be used to set the inferred type (assuming int has type I):
DATA(x) = CONV decfloat34( int / 10 ).
flt = sqrt( n ) + CONV i( int / 10 ).
Even though a LHS variable of type F and the use of function sqrt() imply an outer floating-point calculation, the “/” is computed in type I.
When CONV #( arg ) is bound to a formal parameter of a generic type FT, where the type of arg is AT, the ABAP compiler goes to great lengths to determine a reasonable conversion type CT (the goal of generalization safety mentioned earlier). Some of the rules are:
- If AT is statically known and complies with FT, no conversion is performed and arg is used directly; the compiler just issues a warning (redundant operator). Hereby the calling code, where, for example, AT = C(10), survives a generalization from FTold = C(20) to FT = CSEQUENCE ; even without an unnecessary conversion to STRING.
- For FT = C (generic) and AT = I, the inferred type is CT = C(11), because 11 is the output length of type I. Any character-converted integer fits into a C(11).
- If nothing is known about AT, then FT = NUMERIC yields CT = DECFLOAT34, because it is the numeric type with the biggest value range.
A variant of CONV is the EXACT operator; it corresponds to the lossless statements MOVE EXACT and COMPUTE EXACT. For example, EXACT char4( 'abcde' ) leads to the exception CX_SY_CONVERSION_DATA_LOSS and EXACT decfloat34( 1 /3 ) leads to CX_SY_CONVERSION_ROUNDING.
As for ABAP verbosity, here is another familiar pattern:
DATA x TYPE the_needed_type.
IF test( ) = 'X'. x = some.
ELSE. x = other. ENDIF.
do_something( x ).
The new COND (= “conditional”) operator requires no more keystrokes for the job than it’s worth:
do_something( COND #( WHEN test( ) = 'X' THEN some ELSE other ) ).
It gets even shorter with the new feature predicative method call, which means you can use any functional method call as a logical expression, implicitly augmented with “… IS NOT INITIAL”:
do_something( COND #( WHEN test( ) THEN some ELSE other ) ).
Incidentally, if the required value is an “ABAP Boolean” ('X' for true and ' ' for false), the new built-in function xsdbool() is more convenient than COND:
do_something( xsdbool( x > 1 AND f( x ) = 0 ) ).
xsdbool() is very similar to boolc() which came with 7.02, but its result type is C(1), not STRING, which prevents unexpected results when used for type inference. It also has the right domain for XML serialization.
Returning to COND: If the decision is not a binary one, simply add more WHEN clauses.
COND #( WHEN test1( ) THEN some
WHEN test2( ) THEN other
ELSE default )
If you omit the ELSE clause and all tests are false, the result of COND is the initial value of the type. Or maybe you want to throw an exception if something is wrong:
COND #( WHEN bad( x ) THEN THROW cx_bad( x )
WHEN good( x ) THEN x
ELSE THROW cx_unexpected( x )
If all tests involve the same expression and a set of constant values, this calls for the SWITCH operator (expression-level CASE) instead of COND (expression-level IF):
SWITCH #( x WHEN 1 THEN some
WHEN 2 THEN other
ELSE THROW cx_unexpected( x )
LET There Be Locals
If the value to be tested must be computed first—don’t despair (and don’t add a DATA statement). Almost all constructor operators, including NEW, VALUE, CONV, and the conditionals, support local variable bindings:
COND #( LET t = f( x ) IN WHEN t < 1 THEN 0
WHEN t > 9 THEN 10 ELSE t )
Between LET and IN, there can be any number of var = exp bindings, each of which may use the previous ones. The scope of a LET variable is the remainder of the constructor expression. Being able to access its value outside the expression would be unhygienic, so that is forbidden. However, its existence can’t be concealed completely (due to the aforementioned problems with scope in the ABAP compiler). Therefore, you are required to keep local and normal variables disjoint, cf. Figure 7.
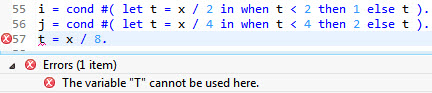
Figure 7
Local may later be re-bound as local, but not used outside expression
LET provides a means to circumvent the problem with intermediate states in assignments like x = VALUE #( … x … ). For example, a swap of structure components can be realized thus:
struc = VALUE #( LET t = struc-c1 IN c1 = struc-c2 c2 = t ).
With locals and conditionals, expressions can easily stretch across several lines. However, their evaluation is not entirely opaque. Using the debugger’s Step Size feature, one can debug into such an expression. In Figure 8, the user has single-stepped to the third WHEN test which, as you can see from the Variables window, will succeed, so the next step will highlight the THEN 50 part.
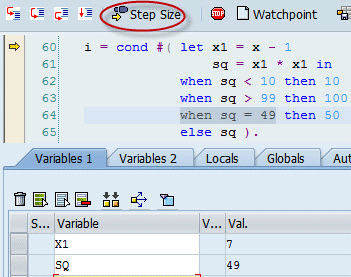
Figure 8
Expression debugging. Current position highlighted, local variables visible
Expressions without “jumps” cannot be debugged into. However, if you feel a computation is too complex, it’s perfectly acceptable to throw in some explicit variables:
do_something( VALUE #( " … very complex expression …
" … want to see result in debugger …
) ).
Using a single-assignment variable, you don’t have to debug into the call to see the value:
DATA(x) = VALUE required_type( … ).
do_something( x ).
(You just lose the possibility of type inference from the formal parameter.) Neither LET variables nor DATAs used in an SSA discipline can be condemned as imperative programming. They are just bindings of intermediate results: a useful functional idiom.
Conclusion
This concludes part 1 of my survey of 7.40 ABAP. You have learned about three closely related concepts that can make everyday programming tasks a lot easier: inline declarations, type inference, and constructor expressions. While you could argue that most of this should have been part of the language from day one, perhaps for the more elaborate forms ABAP can claim to be in line with a general trend: Turning a rather crude imperative language into a more user-friendly tool, by shifting focus from the how to the what. In recent years, concepts from functional programming have finally entered the mainstream.
Sometimes the criticism is heard that functional code is easier to write than imperative code, but harder to read. I would argue that this is a delusion. When you look at imperative code, you quickly come to believe you understand what’s going on, but in fact what you understand is just the micro-effect of single statements on the state. If a program is well-written, the sum of these impressions can give you an appropriate idea of the overall effect. But if it has bugs, you will overlook them. In contrast, understanding functional code includes understanding its correctness.
So, if this first part of the 7.40 ABAP language survey has got you excited to proceed on the path of modern ABAP programming, don’t miss part 2, which presents powerful new operations for internal tables.
Karsten Bohlmann
Karsten Bohlmann is currently a development architect in the ABAP language team. He has been an SAP employee since 1998 and joined kernel development in 2000, where he developed the kernel-integrated XSLT processor and the Simple Transformations language for ABAP-XML mappings. Since 2005, he has been active in the ABAP compiler and virtual machine, spending most of his time on expanding ABAP towards a more modern language.
You may contact the author at karsten.bohlmann@sap.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





