Accessing past payroll information can be confusing if you do not know about the relevant storage architecture and code. Learn how R/3 uses the concept of clusters to store information. Find out about two approaches to access payroll information that is stored in clusters.
Key Concept
For most data pertinent to SAP applications, two methods are available for accessing information stored in the database. You can use either a logical database or import statements/standard function modules. The same rule is applicable while trying to access payroll results. Logical database PNP is available for the first method. You can also use import statements/function modules, which requires more coding. This is commonly referred to as “without PNP.”
Note
I have used the generic name RX to describe the cluster in which payroll results reside. This name varies according to your country grouping; for example, RU for the US, RG for Great Britain, and RX for international. The country groupings and their respective cluster IDs are stored in database table T500L. View the table contents to find out the cluster for your particular country grouping.
You may need to access information stored in payroll results for display in your reports and queries. This technique works for all payrolls that have been executed in R/3 in the update mode, whether they are of the current month or past months. For example, your user may ask for a report that generates the total of basic pay paid to employees within a certain period of time. Retrieving such field information in programs may sometimes be confusing for developers and consultants. Unlike other fields of the infotype, R/3 does not allow you to view these results through the Data Browser.
SAP R/3 uses the concept of clusters to store a variety of information within the HR terrain. The payroll results are no exception. Payroll results in both R/3 and mySAP ERP are stored in the database as clusters in table PCL2.
You can access information stored in payroll results via two approaches. I will start with an explanation of the storage architecture of payroll results and the transaction that can be used to view them. I’ll discuss the two approaches, their advantages, and limitations. I will also provide debugging tips for each. I will draw a comparison that can help you select the approach that best suits your particular scenario. Using an ABAP program or query, functional analysts who have the necessary security and authorizations can access the relevant payroll data by following the steps I’ll provide.
Payroll Data Storage
No matter which approach you follow for accessing payroll results, understanding the architecture for stored payroll results is necessary because it will be helpful in writing the related code. As I mentioned, payroll results are not stored in database tables like other fields of an infotype. Rather, they reside as clusters in the database table PCL2. Two clusters are involved. The first, CU, stores the directory of all payroll runs, whereas the other is used to store actual payroll results. The two clusters are analogous to two database tables having header and detailed information.
Cluster CU contains the payroll directory of all employees. The table PCL2 contains one row with cluster IDs equal to CU for each employee. The directory is stored in internal table RGDIR that is based on the dictionary structure PC261. The key field used to fetch the payroll directory for an employee is the employee number. Each period run is assigned a sequence number (SEQNR).
Cluster RX includes the actual payroll results for each payroll period of every employee. For each row in table RGDIR, an entry exists in table PCL2 that stores the payroll results for the corresponding payroll period. The field SEQNR is used to link the data in the two clusters. The personnel number links with the sequential number from the payroll directory to form the key for storage of payroll results (of a given period) in this cluster. Table 1 provides an overview of the two clusters.
| Payroll directory |
CU |
Personnel number |
RGDIR |
| Payroll results |
RX |
Personnel number and payroll sequential number |
RT, WPBP, V0, etc. |
| Table 1 |
Attributes of clusters CU and RX |
Consider the example in Figure 1. For simplicity’s sake, I have only shown the directory and payroll results of employee X residing in clusters CU and RX, respectively. The directory RGDIR shows two payrolls for January and February 2005 of employee X with the number 00000001. The January and February payrolls are assigned the sequential numbers 00001 and 00002, respectively.

Figure 1
Table PCL2 containing the data in two clusters for employee X
The personnel number (00000001) and the sequential numbers (00001 and 00002) formulate the keys for storing the period payroll results in cluster RX. The keys 0000000100001 and 0000000100002 link the January and February results.
The RPCALCx0 program updates the payroll directory and populates the payroll results in clusters CU and RX. For each payroll executed for an employee in update mode, R/3 adds a new row to the payroll directory with an incremented sequential number. If only one payroll is executed for a particular month, the payroll run is assigned a payroll status (field SRTZA) of A. In case a payroll is re-executed for a given month, the system assigns a different sequential number to the current (recent) payroll run and sets its payroll status (field SRTZA) to A, whereas the previous payroll run is assigned to P (previous result). If a third payroll run occurs, R/3 sets the most recent payroll status to A, the previous payroll run to P, and the oldest payroll run to O. If more than three payroll runs are executed for the same period, the latest run and the one before it are assigned payroll indicators A and P, and all other runs are assigned O.
View Payroll Results
Before trying to access the payroll results in programs and queries, you should view the results stored in table PCL2. You can use transaction PC_PAYRESULT to view them. This transaction reads the results from the various clusters involved and displays them on the user screen. Proceed as follows:
Enter transaction PC_PAYRESULT. A screen appears, as shown in Figure 2.

Figure 2
Transaction PC_PAYRESULT
At the top of the screen in the Personnel number field, enter a suitable personnel number and press Enter. Figure 3 shows the lower part of the screen depicted in Figure 2. The left side of the pane shows the number and name of the employee and the right side shows the contents of the payroll directory for the employee whose personnel number you just entered.

Figure 3
The payroll results are displayed in the right pane
You may change the layout of the displayed data by using the toolbar buttons. Click on the row that pertains to the payroll period in which you are interested. This takes you to the contents of cluster RX of the payroll result in question.
Which Approach Should You Use?
Use the approach that best suits your reporting requirements. The first approach is easier for the developer but has restrictions and limitations. It may only be used in programs that employ the logical database PNP. Moreover, it may not be suitable for coding in user exits and Business Add-Ins (BAdIs).
Conversely, the second method may be used to access payroll results in queries and reports that do not involve the logical database PNP. You can also use it to enhance program functionality with user exits and BAdIs. Table 2 draws a comparison between the two approaches and could help you in making the decision.
| Criteria |
Approach 1 (PNP) |
Approach 2 (without PNP) |
| PNP required |
Yes |
No |
| User exits/BAdI |
No |
Yes |
| Usage in query |
Difficult |
Easy |
| Authorization built in |
Yes |
No |
| Need to know the cluster IDs involved |
No |
Yes |
| Power for devising payroll selection criteria |
Less |
More |
| Table 2 |
Comparison of the two approaches |
Approach 1:
Use Logical Database PNP
The first approach for accessing payroll results in ABAP programs is based on logical database PNP. From Release 4.6, SAP empowered its developers by embedding payroll access functionality in the PNP logical database. To create a program that uses PNP for fetching payroll results, proceed as follows.
Step 1. Create a custom program with transaction SE38. Name your program appropriately, such as Z_READ_ PAYROLL_RESULT. Then click on the Create button, which brings you to the Attributes screen. Enter a description and other relevant entries (Figure 4). Enter PNP as the Logical database and 900 as the Selection screen number. Save your program. This takes you to a screen where you enter the basic code that lays the groundwork to add the full code later. Fixed point arithmetic is checked by default. It is used for accurate program computations. Since you are making a custom program that needs to be used afterwards in a production system, the Customer production program must be selected.

Figure 4
Define attributes of your custom ABAP program
Note
For simplicity’s sake, I have ignored the impact of retroactive accounting for the two approaches.
Logical database PNP is used in many queries and ABAP programs because it offers features such as a selection screen and authorization checks as well as minimizing code.
While defining attributes for the main program, make sure that the selection screen field is assigned the number 900.
Step 2. Define the logical database nodes and create the program selection screen. The next step involves defining the nodes and tables of the logical database. This lets you create the custom program’s selection screen. This screen enables the user to specify the personnel number and months from which to retrieve payroll data. The following code fragment lets you generate the screen:
TABLES: PERNR, PYTIMESCREEN, PYORGSCREEN.
The TABLES statement displays the PNP screen shown in Figure 5.
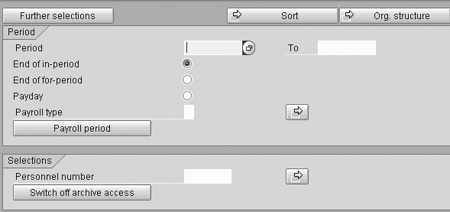
Figure 5
PNP selection screen 900 displayed with payroll and personnel number option
This screen provides a number of fields that let the user view the payroll results of a certain number of employees for given payroll periods. For example, if a user wants to view all the results in 2004, he or she enters 1.1.2004 and 31.12.2004 in the period start and end date fields and checks the End of for- period button.
You also need to define a variable for the PAYROLL node of the logical database PNP. This structure holds the payroll data when the program is executed. Enter the following line of code on the ABAP Editor screen:
NODES: PAYROLL TYPE PAY99_RESULT.
Note
In my example, I used the structure PAY99_RESULT to define the payroll object. SAP offers a number for structures such as PAYUS_RESULT for the US and PAYGB_RESULT for Great Britain. Check to see which structure best suits your requirement.
Step 3. Fetch and display data from the payroll object. In the last step, R/3 reads the required data from the relevant data structure and displays it. This involves coding within the GET PAYROLL event. This is the most important step and requires knowledge of the payroll data object. For more information, refer to the sidebar below, “Data Object Payroll and the GET PAYROLL Event.”
All of the above steps are required to write the code in Figure 6. The code displays basic pay (wage type 0002) for employees within a certain payroll period.
FUNCTION z_hrpa_objmgr_col_standard_fil .
*”————————————————&md
ash;—————————————————
—
*”*”Local Interface:
*” IMPORTING
*” REFERENCE(COL_KEY) TYPE TV_ITMNAME OPTIONAL
*” REFERENCE(TREE_HANDLE) OPTIONAL
*” REFERENCE(KEY_DATE) LIKE OBJEC-BEGDA OPTIONAL
*” REFERENCE(BEGDA) LIKE OBJEC-BEGDA OPTIONAL
*” REFERENCE(ENDDA) LIKE OBJEC-ENDDA OPTIONAL
*” TABLES
*” TREE_OBJECTS STRUCTURE TREE_OBJEC
*” TREE_STRUCTURE STRUCTURE TREE_STRUC
*” COLUMN_CONTENT STRUCTURE ORGNODECON
*” LEGEND_ICON_TEXT STRUCTURE TREELEGEND OPTIONAL
*”————————————————&md
ash;—————————————————
REPORT Z_READ_PAYROLL_RESULT.
TABLES : PERNR,
PYTIMESCREEN,
PYORGSCREEN.
NODES PAYROLL TYPE PAY99_RESULT.
DATA WA LIKE LINE OF PAYROLL-INTER-RT.
START-OF-SELECTION.
GET PERNR.
GET PAYROLL.
LOOP AT PAYROLL-INTER-RT INTO WA
WHERE LGART EQ ‘0002’.
WRITE :/ WA-BETRG.
ENDLOOP.
END-OF-SELECTION.
|
| Figure 6 |
COMPLETE LISTING code |
Approach 2:
Without Logical Database PNP
The second approach is based on explicitly accessing the data from each of the two clusters CU and RX. First, R/3 accesses the entire payroll directory and reads the result that corresponds to the specified period. This approach requires knowledge of the cluster IDs involved. The following steps to access the clusters’ data are required to write the code shown in Figure 7.
DATA: MYKEY(14).
DATA: RT LIKE PC207 OCCURS 0 WITH HEADER LINE.
DATA: RGDIR LIKE PC261 OCCURS 0 WITH HEADER LINE.
REFRESH RGDIR.
IMPORT RGDIR FROM DATABASE PCL2(CU) ID PERNR.
LOOP AT RGDIR WHERE FPBEG LE ‘20041231’
AND FBEND GE ‘20040101’.
REFRESH RT.
MYKEY(8) = PERNR.
MYKEY+8(5) = RGDIR-SEQNR.
IMPORT RT FROM DATABASE PCL2(RX) ID MYKEY.
CLEAR RT.
READ TABLE RT WITH KEY LGART = ‘0002’.
IF SY-SUBRC EQ 0.
WRITE :/ RT-BETRG.
ENDIF.
ENDLOOP.
|
| Figure 7 |
Complete code for approach 2 |
Step 1. Import the payroll directory. Access the entire payroll directory RGDIR stored in database cluster CU of table PCL2 via the IMPORT statement shown below:
IMPORT RGDIR FROM DATABASE PCL2(CU) ID PERNR.
Note
Import only the required data (in my example, RT) from cluster RX. Importing unnecessary data may put an extra load on your system, particularly when the code is run for a large number of employees.
Note
Instead of using import statements, another approach to accessing payroll results would be to use the standard function module
PYXX_READ_PAYROLL_RESULT provided by the function group
HRPAY99_IMPEXP. For more information of its usage and other related function modules, refer to my SAPexperts
article “
Access Loan Data with Ease.”
Step 2. Determine which payroll directory rows to process. When you have imported the payroll directory for the employee in question, you have to figure out how many rows of the directory need to be processed to suit your requirement. A major strength of this second approach is that it gives you more power (with less coding effort) for selecting the appropriate results. You have access to a large amount of information pertinent to the payroll runs. Table 3 shows some of the important fields in table RGDIR that let you formulate the criteria for selecting the payroll runs related to your scenario.
| Field Name |
Information |
| SEQNR |
Sequential number |
| ABKRS |
Payroll area |
| FPPER |
Payroll area for for-period |
| FPBEG |
Beginning date of for-period of payroll |
| FPEND |
End date of for-period of payroll |
| SRTZA |
Payroll indicator |
| RUNDT |
Date of payroll run |
|
Table 3
|
Useful fields of the payroll directory and their meaning |
To better understand the selection process, consider this scenario. Suppose you need the total basic pay amount paid to employee X during the year 2004. For this requirement, you need to read the directory rows that correspond to payroll periods between 01.01.2004 and 31.12.2004 via the LOOP statement shown below:
The code to access the payroll data in step 3 is incorporated within this loop. You entered the code on the ABAP editor screen encountered while creating a program. If you want to read a single month’s payroll result, a READ statement suffices instead of a loop.
Step 3. Import the payroll results from cluster RX. In this step, read the desired payroll results from the relevant cluster via an import statement. First you need to formulate a key for reading the month’s payroll result from the database cluster, variable MYKEY. The employee number and the sequential number are assigned to the first eight and subsequent five characters of MYKEY, respectively. Finally, an import statement reads the desired data (in this case, table RT) corresponding to MYKEY from the database PCL2. The code fragment that deals with this is shown below:
If you want to read a single month’s payroll result, place the above code after the read statement written in step 2. Alternately, place the code within a loop to read payroll results for multiple periods.
The complete list of code that reads and displays the basic pay (wage type 0002) amount paid to employees during year 2004 is shown in Figure 7.
You can also use the code of approach 2 in SAP Query to access payroll information. As I showed in my article “Use Clusters to Access Infotype Texts,” this involves the creation of an additional field and then writing the code in the additional field code.
Troubleshooting Tips for Both Approaches
If you try to access payroll data via programs or queries based on either of the approaches mentioned in this article and the system seems to display erroneous results, you need to check whether R/3 is correctly executing the code and accessing the relevant month’s payroll results. Proceed as follows:
Step 1. Enter transaction SE38. Type the name of the program created in the Program field and click on Display. In the case of a query, access the additional field code with the available editor.
Step 2. For approach 1, place the cursor on the line just after the GET PAYROLL statement. If you use approach 2, the cursor needs to be placed on the IMPORT RGDIR statement. Set a breakpoint by clicking on the stop icon. Alternately, especially when using SAP Query, you may also write the statement BREAK followed by the user name before the function call (for example, BREAK JOHN).
Step 3. Execute the custom program or query. If you’ve set a breakpoint, as mentioned in step 2, the program stops in the debugging mode.
Step 4. Execute each line of the program by pressing F5. This allows you to monitor the values of the variables involved during the payroll information display, which helps you to track the cause of the error. Use the debugger to view the contents of the involved data objects, as shown in Figure 8.

Figure 8
View structure PAYROLL-EVP in the debugger
Note
When using the approach of logical database PNP to access payroll information, understanding the payroll data object and the behavior of the
GET PAYROLL event is critical. It is also a good idea to become familiar with the information that is available while the
GET PAYROLL event is executed. The GET is the event that runs the code between
GET PAYROLL and
END-OF- SELECTION. On the other hand,
PAYROLL is the object that is populated with relevant data on each get event (iteration).
The PAYROLL object is comprised of two important structures, EVP and INTER.
• EVP consists of fields that contain information residing in the payroll directory in cluster CU of table PCL2.
• INTER contains of a variety of structures and internal tables shown in Figure 1.
The most important are the Results Table (RT) and Work Center (WPBP).
The basic layout of the code follows:
START-OF-SELECTION.
..........
GET PERNR
.........
GET PAYROLL.
........
END-OF-SELECTION.
This is the template or basic structure of the program, to help you understand the behavior of the GET events. The above construct behaves like a nested loop. The GET PERNR event runs once for every employee selected during the program execution. For each employee selected, the code between GET PAYROLL and END-OF-SELECTION is executed for all the payroll periods entered by the user on the screen shown in Figure 5. This code conforms to your business requirement. For example, to access the table RT of a given period, you may use a LOOP statement on table PAYROLL-INTER-RT as shown below:
DATA WA LIKE LINE OF PAYROLL-INTER-RT.
GET PAYROLL.
........................
LOOP AT PAYROLL-INTER-RT INTO WA.
ENDLOOP.
........................
During each iteration of the GET PAYROLL event, the PAYROLL data object is populated with the payroll results data (from the clusters CU and RX stored in table PCL2) of the payroll period in question.
Rehan Zaidi
Rehan Zaidi is a consultant for several international SAP clients (both on-site and remotely) on a wide range of SAP technical and functional requirements, and also provides writing and documentation services for their SAP- and ABAP-related products. He started working with SAP in 1999 and writing about his experiences in 2001. Rehan has written several articles for both SAP Professional Journal and HR Expert, and also has a number of popular SAP- and ABAP-related books to his credit.
You may contact the author at erpdomain@gmail.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.



