
What Are the Prospects for Deep Learning?
The data science community is constantly on the hunt for the next blockbuster multi-use algorithm. Ease of use and interpretability have made logistic regression and decision trees analytic staples. But their accuracy and classification stability leave something to be desired. So the industry keeps searching for an algorithm that can decipher key patterns and signals in data.
A long line of fad techniques has come and gone. Deep learning is the latest darling of the data science set. But how likely is this latest algorithm to stick around for the long haul?
Let’s take a stroll through a brief history of machine learning development to shed some light on deep learning.
Explore related questions
Machine Learning Fads and Breakthroughs
I’ll start with the artificial neural networks (ANNs) from which deep learning evolved. In 1943, Warren McCulloch and Walter Pitts proposed the first mathematical model of a neural network. ANNs use the processing of the brain as a basis for developing algorithms that can be used to model complex patterns and prediction problems. Still in use today, ANNs learn by carefully and repeatedly examining the data to define the relationships in it.
ANNs first became a reality in 1958 when Frank Rosenblatt developed the Perceptron and implemented it on custom hardware. But while the Perceptron seemed promising initially, in 1969, Marvin Minsky and Seymour Papert demonstrated its limitations. While most relationships are nonlinear, the Perceptron could describe only relations that were linearly separable patterns. This constraint caused the field of neural network research to stagnate for many years.
Finally, in the mid-1980s, the concept of backpropagation led to a renewed interest in ANNs. Using backpropagation, the neural network can adjust model weights by comparing the computed output with the actual desired output. When trained on suitable data, these neural networks were good nonlinear classifiers. Nonetheless, interest was muted due to a lack of data and/or computing power to train sophisticated networks.
Support vector machines (SVMs), which were introduced by Bernhard Boser, Corinna Cortest and Vladimir Vapnik, became widely popular in the 1990s and early 2000s for use in pattern analysis. SVMs use an optimal hyperplane boundary to divide the data into classes or groups. While some claimed SVMs could address virtually any classification or regression problem, most analysts struggled to select the right required kernel function to provide to the machine learning algorithm. Data scientists needed know the true structure of the data as an input, which meant having a good idea about how the data is separated beforehand. SVMs also proved slow to train, especially on large data with multilevel labels. Overall, an SVM is a good algorithm that generalizes well, but it is hardly a silver bullet.
Data miners and data scientists love decision trees. Invented between 1970 and 1980, a decision tree is a graph that uses a treelike branching method to illustrate every outcome of a decision. Decision trees are easy to use, easy to interpret, and easy to operationalize. They contain many useful features, such as support for continuous and categorical inputs, a clear indication of most important variables, and automatic handling of missing values. They also require minimal computation for classification. But decision trees are not as accurate or robust as other approaches. Small changes in the data can cause big changes in the tree.
The solution was to grow hundreds or thousands of decision trees using bootstrap sampling, randomize the inputs for each tree and then combine the decision trees into a single, more accurate model. One example is the random forest, which grows numerous deep trees at random. The random forest is commonly used as an initial model for Kaggle predictive modeling and analytics competitions as well as for other machine learning applications. Another tree-based model, gradient boosting, is probably the most accurate available algorithm out of the box. Many of my customers rely on boosted trees to solve difficult problems.
What Does History Tell Us About Deep Learning?
What does all this history tell us about the prospects for deep learning? As you can see in the Google Trends graphic (Figure 1), search traffic for the term “deep learning” has grown exponentially over the past five years compared with stable interest in the other algorithms.
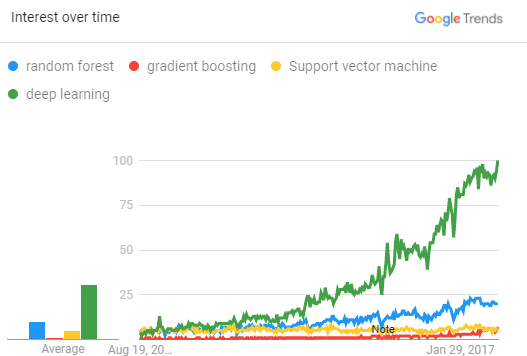
Deep learning is a type of machine learning that uses a many-layered neural network to produce highly accurate models. Deep learning has taken off for two reasons. First, organizations of all sizes finally have access to more and bigger data, including unstructured data. Second, the massive computing power necessary to train models on big data in reasonable time frames is now available at an affordable cost.
Is there a downside to deep learning? Deep networks with five or more hidden layers commonly have millions, if not billions, of parameters to estimate. One of the risks when fitting big models is overfitting the training data, which means the model can have poor predictive performance. Many deep learning techniques help prevent overfitting, such as pruning in decision trees, early stopping in neural networks and regularization in SVMs. But the most simple and efficient method is to use more data.
According to my coworker, Xiangqian Hu, deep learning is popular for three “big” reasons: big data, big models and big computations. Big data requires big modeling, and big modeling requires big computations (such as graphics processing units [GPUs]).
Of course, these factors also create big challenges for deep learning. Big data is expensive to collect, label, and store. Big models are hard to optimize. Big computations are expensive. At SAS, we’re focusing on coming up with new ideas to overcome these challenges and make deep learning more accessible to everyone.
A Diverse Set of Applications
Ultimately, deep learning is popular because it can be applied to many applications, including:
- Speech to text: Deep recurrent networks, a type of deep learning, are great at interpreting speech and responding accordingly. Personal assistants are a good example. Just say, “Hey, Siri,” ask any question, and your device will respond with the correct answer.
- Messaging bots: Bots in the workplace can talk to you via text or speech, understand context using natural language interaction and then run deep learning to answer analytical questions, such as “Who is likely to churn?” or “What are expected sales for next year?”
- Image classification: Deep learning is very accurate for computer vision. It can, for example, detect manufacturing defects in computer chips.
- Object detection: Object identification in images and videos has improved tremendously due to deep convolutional networks, another type of deep learning. SAS uses convolutional networks to evaluate athletes’ performance on a field in real time and to track migration habits of endangered species through footprint analyses.
- Health care: Deep convolutional networks are being used to identify diseases from symptoms or X-rays, or determine whether a tumor is cancerous.
- Robotics: Most robot capabilities owe a fair amount to deep learning.
- Banking: Deep forward networks are being used to detect fraud among transaction data.
Could deep learning be just another fad, or is it destined to serve for many years to come? No one knows what the future holds. But right now deep learning is the best universal algorithm available – bar none. So sharpen your deep learning skills and keep them in your pocket. They’re sure to serve you well – at least until something bigger and better comes along.



