Rehan Zaidi explains how the use of subgroups within a Regular expression (Regex) allows you to write short code for solving complex programming problems. See six examples of how such regular expressions in conjunction with a REPLACE statement can save time and coding effort.
Key Concept
A Regular expression (Regex) is composed of literals and operators, both of which are special characters used to search for a certain pattern within a text stream. Specifying subgroups within a Regex lets you match one or more subsets of a given text. The matched content, stored in registers and used in conjunction with a REPLACE statement, can be used to fulfill data conversion requirements.
From SAP NetWeaver release 7.0, ABAP allows use of POSIX-style Regular expressions (Regexes) in your programs. Regexes let you write code composed of a few lines that would otherwise make the program too verbose if an alternate approach were used. Via Regexes, you can specify subgroups. If used wisely, subgroups can help write validations and conversion code very quickly and easily.
The purpose of this article is to provide a detailed explanation of subgroup use in Regex programming in conjunction with other operators and the REPLACE statement. I start with a brief explanation of the important elements and then explain what subgroups and subgroup registers are and how they fit into the landscape of Regex programming. Finally, I show six problems that can be solved using Regexes and the REPLACE statement.
I have selected examples that help you better understand the concept of Regex subgroups. The examples also help solve issues faced in real-life scenarios in development work. While a detailed explanation of Regex programming is beyond the scope of this article, I do discuss the basic operators needed to understand the subgroup-related examples and use the standard program DEMO_REGEX_TOY for illustration where required.
Brief Background of Regex Concepts and Registers
A Regex is composed of literals and operators. These operators are special characters used to search for a certain pattern within a text stream. These are typically used for validation, conversion or translation, and extraction of data from the given text. Table 1 shows the commonly used operators within a Regex.
| Operator |
Meaning |
.Dot
|
This is used for matching a single character
|
| * |
Any number of occurrences (e.g., 0, 1, or more) of a certain character or a set of characters |
?
|
Either no or a single occurrence of a given character or set of characters
|
+
|
Denotes a single or multiple occurrence (e.g., 1 or more) of a character or a set of characters |
| ^ |
a) Denotes negation when used within box brackets []
b) Also used for representing the start of a text line
|
?=
|
A preview condition |
?!
|
A negated preview condition |
1, 2
|
Used for placeholders for subgroup registers (also known as back-referencing operator) |
$
|
Indicates end of a string
|
d
|
Represents a digit (from 0 to 9)
|
s
|
A blank space
|
w
|
Denotes an alphanumeric character
|
u
|
Represents a single letter
|
<
|
Denotes start of a word within the text
|
>
|
Denotes end of a word within the text
|
| { } |
Indicates the number of occurrences of a character or a set of characters, such as a {1} means one “a”. Ab {2,3} means two or three occurrences, “ab” such as abab, ababab. |
Table 1
Commonly used Regex operators
When you need to match the special characters (operators) such as +, “, and ? in a given text, you must add an extra backslash before the operator in question. For example, the respective characters are then written as +, ", ?, $, ^, (, ), [, and ]. In this case, these characters are then treated as literals rather than as operators.
For more on Regex formation, refer to this link: https://help.sap.com/abapdocu_740/en/abenregular_expressions.htm.
In addition to the ones shown in Table 1, you have the operators (...) and (?: ...). These two operators allow you to create units known as subgroups within your Regex. For the operator (...), the matched substrings (of the character string for which the Regex is processed) are stored in registers. For multiple groups, these are stored in the correct order in the respective registers (such as register 1, 2, and so on). You can specify an operator 1, 2, or 3 corresponding to each subgroup within the Regex after the given subgroup. These operators (e.g., 1, 2) are also known as back-referencing operators, and they act as placeholders for the string saved in the appropriate register.
The REGEX addition of the REPLACE and FIND statements can be used to process a text stream using a Regex. When you are using the REPLACE statement, the special characters $1, $2, and $3 can be used to access the content of the subgroup registers. When used along with other operators, they are a powerful tool for the replacement and conversion of data.
In addition to the REPLACE and FIND statements, SAP also provides ABAP standard classes CL_ABAP_REGEX and CL_ABAP_MATCHER for processing text based on Regexes. However, my primary emphasis is on the REPLACE statement.
Problems Involving Subgroup Registers and the REPLACE Statement
In this section, you see a number of problems that, without the use of Regexes, would require a lot of coding. These involve Regexes with subgroup registers used in a single REPLACE statement. Note that it may be possible that the examples shown can be solved by a number of Regexes.
For the REPLACE statement, when the replacement has been done successfully, the return code SY-SUBRC value is equal to 0.
While using Regexes, make sure to include the addition REGEX in the REPLACE statement. Otherwise, the statement does not yield the desired result.
Example 1: Date Conversion into SAP Internal Format
Let's examine the requirement for converting a date (available in output format) into the internal SAP format. For example, 05/13/2015 is a commonly formatted date in a string the program should convert into an internal format of 20150513 for SAP requirements. You can use Regexes in conjunction with the REPLACE statement for fulfilling this formatting change. For the sake of simplicity, I assume that the date is correctly entered and only the conversion is required. The code for this is shown in Figure 1.
replace regex '(d{2})/(d{2})/(d{4})' in date with '$3$1$2'.
Figure 1
Code for converting the date in text into an SAP internal format
The original date is contained in the variable DATE, and after the conversion, the new format replaces the original version. The Regex used in this case is (d{2})/ (d{2})/ (d{4}) and consists of the following parts:
- The first part matches the month portion of the month (the first two digits) and is denoted by d{2}. This is stored in the subgroup register 1.
- The second part finds the next two digits (i.e., the day using d{2}) and stores it in register 2.
- Finally, the third part recognizes the four-digit year in the date and stores it in register 3.
You do not need the forward slashes; therefore, they are not included in the parentheses and ultimately are not stored in the register. Since all three register values are to be used in the conversion, use the placeholders $1, $2, and $3 in the replacement string like this $3$1$2. After the conversion the year is followed by the month and then the day. When the date 05/13/2015 is processed by the REPLACE statement, the content of the subgroup registers is shown in Table 2.
Register 1
|
05
|
Register 2
|
13
|
Register 3
|
2015
|
Table 2
Register contents
Since I used the “$3$1$2” as the replacement string within the REPLACE statement, once it is executed successfully, the variable date contains the date in SAP internal format as shown in Figure 2.
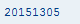
Figure 2
Converted date
Example 2: Removing Repeated Words from a Sentence
Here is an example of how to read a sentence and remove duplicates from it. You take as input a string containing adjacent repetitive words.
The idea of this example is to use the subgroup content placeholders (such as 1 2) within a Regex. Consider the following string: This is a very very long sentence sentence that must be corrected.
When the program is run, the repetitive words (very and sentence) must be removed. The code that deals with this requirement is shown in Figure 3.
REPLACE ALL OCCURRENCES OF regex '(<w+>) 1' in str with '$1'.
Figure 3
Removing adjacent duplicate words from a string
- The first part matches a single word. I used start word (<) and end word (>) operators. The w+ identifies a word consisting of alphanumeric characters (this part is enclosed in parentheses as you want the value to be stored in subgroup register 1).
- The second part is denoted by the backtracking operator 1, which ensures finding adjacent repetition of the word that was found by the first part of the Regex (stored in the subgroup register 1).
Two repeated adjacent words (via the Regex shown) are replaced by a single word (content of subgroup register 1 denoted by $1 in the replacement string). In this way the REPLACE ALL OCCURRENCES finds and replaces all duplicates from the long string. When no repetition is found, the subgroup register is never populated, and thus no replacement takes place.
For the string shown, on the first match, the content of the subgroup register 1 is Subgroup Register 1: very.
The backtracking operator ensures that only repeated words are to be removed. For the string shown, the program returns the clean string as shown in Figure 4.

Figure 4
Duplicates removed
Example 3: Validation and Conversion of Telephone Numbers
Let’s now consider another requirement that you can solve using Regexes and subgroup registers. Suppose you have a US telephone number field (in the format xxxxxxxxxx) that you need to verify. If verified, it needs to be converted to the format +1(xxx) xxx-xxxx. If the telephone number entered is 2331231234, it must be converted to +1(233) 123-1234. Any number that is not correct in length must give an error. Even if any invalid characters are contained in it, an error should result.
For the sake of this example, assume that the telephone number is stored in the variable MYNUMBER that is 16 characters in length (I kept it long in order to store the extra characters added as a result of the conversion). The code for addressing this requirement is shown in Figure 5.
data : mynumber type char16.
….
replace regex '^(d{3})(d{3})(d{4})s{6}$' in MYNUMBER
with '+1($1) $2-$3'.
if sy-subrc ne 0.
write: 'Number Invalid'.
else.
write : mynumber.
endif.
Figure 5
Code for checking or converting the telephone number
The REPLACE statement is used along with the Regex '^(d{3})(d{3})(d{4})s{6}$'. The Regex here consists of four parts:
- The first part matches the three first three digits in the telephone number represented by d{3}. This is stored in the subgroup register 1.
- The second part finds the next three digits of the number (stored in register 2).
- The third part identifies the last four digits contained in the telephone number. These are stored in the third register.
- Finally, the fourth part of the Regex ensures that after the number six, blank characters are included. This is not stored in any register.
The ^ and $ in the Regex ensures that the string under consideration starts with three digits, is followed by seven digits, and ends with six spaces. Once the program code is run for the number 2331231234, the contents of the register are shown in Figure 6.

Figure 6
Content of subgroup registers
Since I specified WITH +1($1) $2-$3 in the REPLACE statement, the international dial code +1 is added as a prefix. That is followed by the contents of the first register enclosed in brackets, then a single space followed by the content of the third and fourth registers separated by a hyphen. This is shown in Figure 7.
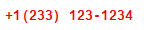
Figure 7
Converted telephone number
The beauty of the REPLACE and Regex code is that it both verifies the correctness of the telephone number and converts it into the specific format. If the number is not correct, SY-SUBRC is set to 4. Otherwise, the converted number is printed on the user screen.
Example 4: Removing Unwanted White Spaces from a String
Following is another requirement that can be solved using Regexes and subgroup registers. In many cases, you may be required to correct (clean) data received in files before uploading it into the SAP system. It may be possible that a field contains extra white spaces throughout (between words or symbols). For example, the name JOHN JONES BARTLETT is wrongly stored as JOHN JONES BARTLETT. In this case you are not sure of the number of words in the string or the number of spaces contained between the adjacent words. The correct form must have one—and only one—blank space between the words.
For the sake of this example, assume that the string from which spaces are to be removed is stored in the variable MYSTRING. The code for this is shown in Figure 8.
replace all occurrences of regex '(<w+>)(s)s*' in MYSTRING
with '$1$2'.
Figure 8
Code for string correction
The REPLACE ALL OCCURRENCES statement is used along with the Regex (<w+>)(s)s*. The Regex here consists of three parts:
- The first part matches every word in the string represented by <w+>. This is stored in the subgroup register 1.
- The second part finds a single space after the word that is found. The single space is stored in the subgroup register 2.
- The third part identifies any number of blank spaces after the single space found earlier. This is not stored in a register (hence, no brackets are used).
Once the program code is run for the string JOHN JONES BARTLETT, on the first match the contents of the register are as shown in Table 3.
| Register 1 |
JOHN |
Register 2
|
A single white space
|
Table 3
Register contents for the first match
Similarly for the second word, the contents are shown in Table 4.
Register 1
|
JONES
|
Register 2
|
A single white space
|
Table 4
Register contents for the second word
Since I specified WITH ‘$1$2’ in the REPLACE statement, the first two words shown in Figure 9 (e.g., JOHN JONES) are followed by a single space in the resulting string and thus any unnecessary spaces are trimmed.
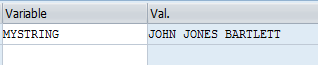
Figure 9
Corrected value
For the third word, the match does not take place, so the REPLACE statement has no effect.
The content of the string after the execution of the REPLACE statement is shown in Figure 9.
Example 5: Removing Comments from ABAP Code Stored in an Internal Table
Now let’s look at how to remove all comments from an ABAP program. (For the sake of this example, assume that the source code of the program is stored in the internal table IT_CODE.) The code for addressing this requirement is shown in Figure 10.
REPLACE ALL OCCURRENCES OF REGEX '(^*.*)|([^"]*)("*.*)'
IN TABLE itab WITH '$2'
DELETE itab WHERE table_line IS INITIAL.
Figure 10
Code for comments removal
- Either begin with an asterisk (*) and are then followed by any number of characters (denoted by .* in the regex expression portion (^*.*))
- Or any number of characters other than (“) followed by a (“) denoted by ([^"]*) ("*.*)
If a line that begins with an * is encountered, the Regex (^*.*) is matched. In this case, the content of the registers 1, 2, and 3 for the line shown in Figure 11 is shown in Figure 12.

Figure 11
Line with an * at the beginning
Figure 12
Registers 1, 2, and 3
Since I used ‘$2’ as the replacement, the line of code in the internal table is replaced with a totally blank line. The content of the second register is blank (and the first subgroup register’s content is totally ignored).
Let’s now consider another case. When you have a line that has ABAP statements written followed by ” and then the comments, the line matches the Regex pattern ([^"]*) ("*.*). For example, if the content of the ABAP line is the one shown in Figure 13, the subgroup registers have the contents shown in Figure 14.
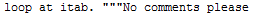
Figure 13
ABAP code line to be processed
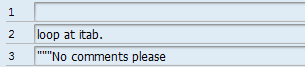
Figure 14
Subgroup registers 1, 2, and 3
Since I specified that the replacement would be composed of only the content of register 2 (via placeholder $2), the REPLACE statement when executed removes the comment and the line now in the internal table becomes the one shown in Figure 15.
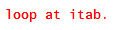
Figure 15
Comment removed from line
The IN TABLE addition in the REPLACE statement ensures that the replacement is done for all lines of the internal table. Finally, use a DELETE statement to remove all lines that are blank. The blank lines are the result of the replacement carried out on lines beginning with an *.
Example 6: Adding Commas in Amounts
The sixth requirement is to insert commas into a numerical value. The idea of this example is to explain the use of the registers in conjunction with the preview operators [the preview condition (?=) and negated preview condition (?!) ].
Say you have an AMOUNT string with values such as 1000, 10000, and so on. You need to insert commas at appropriate places to create an easily legible value, such as 1,000 or 158,890. As with any numerical value, when the amount is less than 1,000, then it does not need any commas. The code for addressing this requirement is shown in Figure 16.
replace all occurrences of regex '(d)(?=(d{3})+(?!d))'
in amount with '$1,'.
Figure 16
Code for inserting commas in an amount string
The REPLACE ALL OCCURRENCES statement is used along with the Regex (d)(?=(d{3})+(?!d)). The Regex tries to find a digit (denoted by d) preceding the specified preview condition. In the preview condition, you find a sequence of specifically three digits [denoted by (d{3})+] without any trailing digit ensured by the negated preview (?!d). In short, you want to match a single digit followed by a multiple of exactly three digits (i.e., 3, 6, 9, and so on, as seen in 1987 or 2654321).
Every matched digit fulfilling the preview condition on its right is stored in the subgroup register 1. Since I have specified WITH ‘$1,’ in the REPLACE statement, this is replaced with itself followed by a comma. The REPLACE ALL OCCURRENCES statement carries out the replacement of all such digits that have a multiple of three digits to their right. This, therefore, replaces every third digit from the left with a preceding comma in the amount string.
For example, the numeric value 8000 results in the subgroup register 1 having a value of 8. There is only one match found. This is replaced with 8, and the resulting string is 8,000. For the amount string having a value of 800, since there is no digit with three digits to the right of it, no replacement is performed.
Let’s look at a larger numerical value string. The amount 8000000 has two matches. The replacement performs the conversion as shown in Figure 17.

Figure 17
Converted amount with exactly two sets of three digits
Rehan Zaidi
Rehan Zaidi is a consultant for several international SAP clients (both on-site and remotely) on a wide range of SAP technical and functional requirements, and also provides writing and documentation services for their SAP- and ABAP-related products. He started working with SAP in 1999 and writing about his experiences in 2001. Rehan has written several articles for both SAP Professional Journal and HR Expert, and also has a number of popular SAP- and ABAP-related books to his credit.
You may contact the author at erpdomain@gmail.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.



