/HANA
Gain an understanding of how to use the new InfoProvider types introduced with SAP NetWeaver BW on SAP HANA, such as SAP HANA-optimized InfoCubes and DataStore Objects. Learn when and how to use them to take full advantage of the in-memory computing capabilities within SAP NetWeaver BW on SAP HANA. Doing so enables your organization to dramatically shorten the time it takes to load data and provide required information for reporting.
Key Concept
SAP NetWeaver BW on SAP HANA introduces new InfoProvider types that are optimized for the use of in-memory computing capabilities. As companies deploy SAP NetWeaver BW on top of SAP HANA, there are significant improvements in the area of data modeling that enable them to implement a much leaner Layered, Scalable Architecture. This approach results in a shorter time-to-market of developments of new applications and data models with SAP NetWeaver BW. Additionally, data loading cycles are shortened.
Traditionally business systems are deployed in a three-tier, client-server architecture in which the end users access applications on their desktop clients. With SAP NetWeaver BW, the data for these applications resides within various database management systems. The heavy workload of extracting, harmonizing, integrating, and consolidating data — thus transforming it into valuable information — occurs in the application tier. With SAP NetWeaver BW-based business solutions, the application layer typically consists of several ABAP application servers.
The database layer usually becomes a bottleneck as there is a lot of data traffic between the application and database layers caused by frequent data reads from the database into the application layer. With SAP HANA, this dramatically changes.
With the technology and software behind SAP HANA, application logic can be executed in the in-memory database layer with incredible speed, decreasing the need of transferring large data sets back and forth between the database and application servers. Multi-core CPUs combined with massively parallel processing (MPP), in-memory, and columnar constructs enable data-intense operations to occur close to where the data is stored. For example, by moving DataStore Object (DSO) activation runtime from the application layer to the database layer, the processing time is improved on average by a factor of 10 to 15.
Figure 1 outlines the move of application runtime to the in-memory database layer.
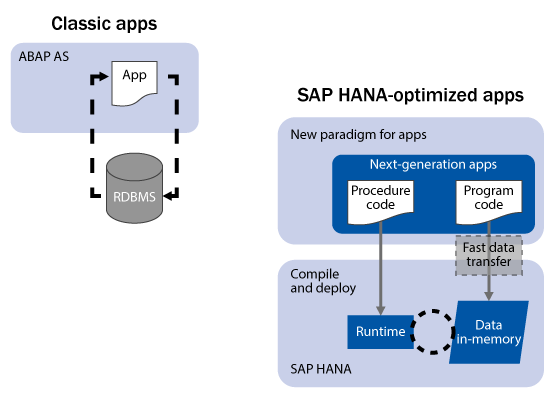
Figure 1
Push of application runtime to the in-memory database layer
SAP NetWeaver BW is one of the first SAP solutions that can use SAP HANA as the underlying database. After migrating the relational database management system (RDBMS) of an existing SAP NetWeaver BW system to SAP HANA, new InfoProvider types become available: SAP HANA-optimized DSOs and SAP HANA-optimized InfoCubes. Let’s go more into detail about the benefits of converting existing DSOs and InfoCubes to these new types of InfoProviders.
SAP HANA-Optimized DSOs
SAP HANA-optimized DSOs become available in an SAP NetWeaver BW system as soon as SAP HANA is used as the underlying database. Existing DSOs can be converted to optimized versions either manually within the Data Warehousing Workbench or all at once in a batch process via transaction RSMIGRHANADB.
With the conversion of a standard DSO to an optimized one, several things change. Most importantly, the activation of the DSO is executed in the database layer only. No round trips to the application server are needed any more. In fact, the application layer is not involved any more at all in the activation process, other than triggering the process and managing the update of request, log, and control tables (Figure 2).
We have seen activation time improvements for our Ramp-Up customers by a factor of 30 and greater after converting to SAP HANA-optimized DSOs.
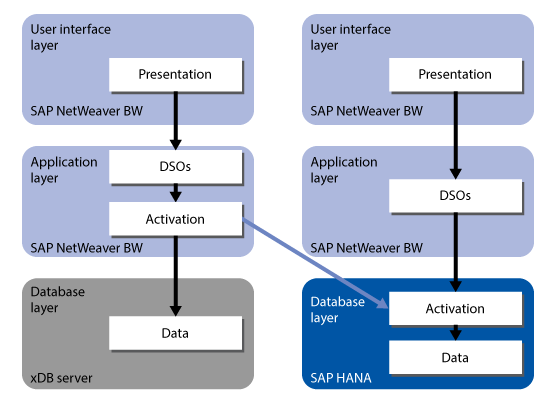
Figure 2
Activation of an SAP HANA-optimized DSO
The way the data of a DSO is stored in the database changes as well to take advantage of the in-memory computing capabilities of SAP HANA. Conceptually, a standard DSO has three data containers:
- For the current data (current image)
- For the recently uploaded data (future image)
- For the result of the differences between the current and the future images (delta image, the result of data activation)
In a traditional SAP NetWeaver BW system deployed on a relational database, these three containers are represented as individual tables, also known as the new data table, active data table, and change log table.
With an SAP HANA-optimized DSO, the basic concept of the activation doesn’t change. However, the data is stored differently (Figure 3). Newly uploaded data (i.e., the future image) is stored first in a columnar table that is called the activation queue. The active data (i.e., the current image) is stored in a temporal table that contains the main index, history index, and delta index. The change log is generated as a calculation view and not stored in a table any more. By replacing the change log table with a calculation view, storage of redundant data is avoided.
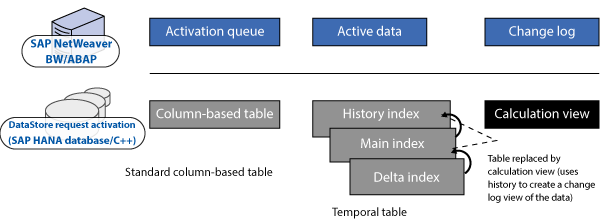
Figure 3
The structure of an SAP HANA-optimized DSO
The SAP HANA-optimized data structures allow faster access to data and also accelerate the process of writing into those structures. Data loads of DSOs, without including activation time, run on average at least twice as fast as they do without SAP HANA. For even faster access to SAP HANA-optimized DSOs for reporting, the Surrogate ID (SID) generation process has been improved, too, taking advantage of the optimized data structures.
It’s also important to mention that the conversion of a standard DSO into an optimized version has no impact on existing data flows. No remodeling of transformations, MultiProviders, or queries is required.
SAP HANA-Optimized InfoCubes
Similar to SAP HANA-optimized DSOs, standard InfoCubes can be converted into optimized InfoCubes either manually or in one batch process via transaction RSMIGRHANADB.
The structure of an SAP HANA-optimized InfoCube looks flatter than the structure of a standard InfoCube. Dimension tables do not exist anymore, with the exception of the technical dimension that includes the request ID, package ID, and record number. There is also no E fact table anymore. With the old concept, there is an E fact table for compressed request data and an F fact table for all uncompressed requests. The purpose of those data structures is to speed up the querying of standard InfoCubes in which the data resides in relational databases.
With SAP HANA as the underlying database for SAP NetWeaver BW, artifacts like the extended star schema are not necessary any more. Flat structures are a better fit for SAP HANA, and, thus, the structure of an optimized InfoCube doesn’t require a second fact table and dimension tables anymore. The single fact table contains the master data SIDs, which results in fewer required database joints once a query is executed (Figure 4).
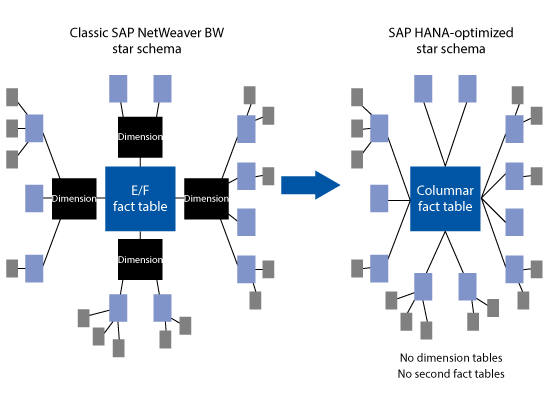
Figure 4
New structure of an SAP HANA-optimized InfoCube
As mentioned earlier, it is now possible to report directly on any InfoProvider while automatically taking advantage of in-memory technology. In the past, many InfoCubes have been built for the sole purpose of making data of a DSO available for reporting. Querying a DSO directly was usually not a good idea because it came with constraints from a reporting performance perspective.
Because those restrictions are obsolete with SAP HANA, many InfoCubes won’t be required any more because reporting directly on a DSO is faster now. A question might come up whether using InfoCubes makes any sense at all in the future. InfoCubes and DSOs still follow different data management processes. For example, a DSO has predefined key fields that determine the delta calculation. In some scenarios, the maximum of 16 key fields is not sufficient. With an InfoCube, there is no such limitation; all characteristics are basically treated like key fields.
Another important aspect to keep in mind is that it’s more difficult to consolidate or merge data sets with different granularities from different sources into one DSO. This is an easier task to accomplish with an InfoCube. For example, suppose you want to create an InfoProvider that consolidates information coming from two sources. Furthermore, one source provides the data with day and month information, while the other source only provides month information. To merge those two data sets into one InfoProvider is usually an easier task with an InfoCube.
Even though we expect to see fewer InfoCubes in the future with implementations in SAP NetWeaver BW powered by SAP HANA, InfoCubes still serve as the better choice of InfoProvider in some scenarios.
Converting standard InfoCubes to SAP HANA-optimized InfoCubes doesn’t have any impact on associated queries, MultiProviders, and transformations. Everything works exactly the same way as before and doesn’t require any adjustments.
Utilizing Logical Providers within SAP NetWeaver BW
Today, within SAP NetWeaver BW, there are MultiProviders and Virtual Providers that provide logical modeling constructs. It has long been a best practice to build BEx queries against MultiProviders, as this provides you the flexibility to remove the dependency on the query being tied to the structure of the InfoCubes as well as provides a union of data from InfoProviders that store data. This concept remains the same with SAP HANA.
Virtual Providers actually may be used more in an SAP NetWeaver BW on SAP HANA environment because in many cases, data that has been stored in cubes has gone through extraction, transformation, and loading. Fundamentally, logical modeling offers benefits in terms of flexibility and duplicate data management. Moving to more logical modeling over time creates benefits such as data that is more current (less latency), as well as having a reduced database size.
Prakash Darji
Prakash Darji is an experienced professional with more than 10 years of end-to-end experience in enterprise software. He has a broad depth of experience including corporate strategy, sales, product management, architecture, and development. He has experience in product launch activities, including positioning, packaging, and pricing. He has delivered numerous product releases in a variety of capacities through his career. He thrives on building high-performing, scalable teams to achieve strategic deliverables, whether they close strategic sales deals, roll in product features, or roll out new releases. He is a recurring author for several publications and a speaker at SAP conferences around the world. Prakash is on LinkedIn at https://www.linkedin.com/in/prakashdarji.
You may contact the author at editor@BIexpertOnline.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.

Daniel Rutschmann
Daniel Rutschmann has been with SAP for more than 11 years, with a strong focus on enterprise data warehousing throughout his entire career, especially in the area of SAP NetWeaver BW. He has held different roles within SAP Consulting over several years, building a strong relationship with customers from various industries around the globe. His expertise is based on many years of consistently delivering successful solutions and IT architectures. Today, he is director for SAP NetWeaver BW on SAP HANA and part of the solution management team for data warehousing solutions and the SAP HANA platform.
If you have comments about this article, or would like to submit an article idea, please contact the BI editor.
You may contact the author at daniel.rutschmann@sap.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.