Management
Learn a 15-step methodology for executing forecasting projects in SAP Advanced Planning and Optimization. Understand the most common methods of statistical analysis. Learn best practices for implementing these methods in practice.
Key Concept
Forecast strategies are used in SAP Advanced Planning and Optimization to decide how forecast values are calculated. Selecting a method depends on characteristics of the data, including seasonality, linear trends, and which data is emphasized.
Statistical forecasting is a strong feature of the Advanced Planning & Optimization (APO) Demand Planning (DP) suite and a lot of companies look at this capability of APO for an effective demand planning process. The recent version of APO (SCM 7.0) covers a wide range of statistical forecasting models. However, mere availability of models does not ensure the best forecast result unless they are used effectively. The first few questions that probably come to mind for any company looking for such a tool are:
- What are the best practices for using the APO statistical forecasting tool?
- How do I know which model best meets the needs of my business (as there are lots of models)?
Based on our experience of executing such statistical forecasting projects for clients from different industries, we have put together a methodology for executing such projects. The methodology is broken into 15 logical steps. We also provide a set of tips and tricks for effective use of this tool and a set of case studies.
Step 1. Finalize the Scope of the Statistical Forecasting Project
In any statistical forecasting project, the common tendency is to do statistical forecasting for every possible stock keeping unit (SKU) that the organization sells. However, it is important to finalize the scope of the project for two reasons.
- Statistical forecasting does not give the desired result in certain cases
- Sometimes being selective gives quicker results
- Forecasting does not give the desired result for certain SKUs, including these:
- New SKUs for which very little history is available and which do not closely mimic the sales behavior of existing SKUs (where like modeling cannot be used).
- SKUs that the organization wants to discontinue in the next few months.
- Purely promotional SKUs that are sold for a very short period during the year, such as Christmas.
- Highly seasonal SKUs for which very little history is available. Ideally a statistical forecasting tool needs at least 24 to 36 months of history of such SKUs to identify seasonality.
- SKUs for which there is a permanent capacity constraint (i.e., the organization always sells less than the original demand of the SKU as it has a constraint in production capacity).
- SKUs with highly variable or unpredictable supplier lead time and production lead time. Variability during replenishment skews the actual demand and makes forecasting unreliable.
From our experience, it is also important to be selective while starting such a project. A quick ABC analysis of SKUs based on sales volume can be handy here. Identify those SKUs that contribute 80 percent of sales and put most of the effort of model selection in these SKUs. If by better statistical forecasting, the forecast accuracy for these SKUs can be improved, it will have a positive effect on the overall business and can deliver quicker results. While in the long run, forecasting needs to be extended to all SKUs, it is always better to start with A and B category SKUs.
Step 2. Have the Right KPIs Before Starting the Project
The final forecast accuracy is the most common key performance indicator (KPI) for any DP implementation. However, if statistical forecasting is in scope, it is better to have a KPI on statistical forecast accuracy as well. Otherwise, there can be lot of manual adjustments once the statistical forecasting is done. The final forecast may be close to actual sales – that means good overall forecast accuracy does not ensure that statistical forecast accuracy is also good. Over time the objective should be to improve statistical forecast accuracy so that it needs minimum manual intervention.
Note
When we refer to a forecast, we mean the final consensus forecast. This
can be different from a statistical forecast. Generally, statistical
forecast numbers can be manually changed wherever required by demand
planners or sales people. These changes may be necessary as statistical
forecast numbers are created from history and may not include all
real-time market realities. Sales representatives or planners who meet
customers on a regular basis can provide input that needs to be
incorporated in the consensus forecast. Therefore, in some cases the
statistical forecast numbers are changed.
- Do not have unrealistic expectations
- Do not set very short-term targets
Example of Unrealistic Goals
A good example of this is a metal company that wants to improve statistical forecasting accuracy from its current level of 65 percent to 90 percent by doing a statistical forecasting project for three months. Clearly these kinds of targets are unrealistic. Also remember the law of marginal improvement – it takes much more effort to improve the accuracy by 5 percentage points if a company is already running with 85 percent efficiency (i.e., improving from 85 percent to 90 percent) than a company running at 65 percent efficiency (i.e., improving from 65% to 70%).
Another caution is not to set short-term targets. A good example of this is a consumer goods company that only bothers with its forecast accuracy for the next month (i.e., M+1 accuracy %). Any statistical forecasting tool’s forecasting results need to be analyzed at least for next few time periods to understand the quality of the result. For the next month, if for some unforeseen reason sales for a product suddenly drop by 50 percent, it is difficult for any statistical forecasting tool to predict this. However, that does not necessarily mean that the tool is not good or that the forecasting models selected are not appropriate.
Ensure that the KPIs are set on forecastable SKUs and not on all SKUs. This way you do not mix up the accuracy of SKUs with a stable sales pattern and those with an erratic pattern.
Step 3. Decide the Level of Forecasting
Deciding on the right level of aggregation is a critical step in any statistical forecasting project. Aggregation can be at three different dimensions:
- Time aggregation (whether to forecast at a weekly or monthly level)
- Product aggregation (whether to forecast at the most detailed level, say for an individual SKU, or at an aggregated level, say product group)
- Location aggregation (whether to forecast at the most detailed level, say individual customer or distribution center, or at an aggregated level, say at country level)
This choice of level need not be uniform for all a company’s products. For example, a food company follows a weekly planning window for all its shelf stable products but a daily window for its chilled and dairy product categories. A tobacco company does forecasting at the distributor level for its large selling products, but for its small selling categories, it forecasts at a national level.
When an aggregation level is too high, it results in high forecast inaccuracy due to reasons such as:
- Forecast models are executed on smooth data and miss lower-level patterns.
- Forecasting at this level may not be good from an execution perspective. Forecasting at a national level may not be directly useful to company’s sales force that generally handles a particular territory or region. In this case, the forecast needs to be disaggregated.
When the aggregation level is too low, it results in high forecast inaccuracy due to reasons such as:
- A very low level can provide data that cannot be forecast statistically
- Decimal dust: Low forecast values might be rounded off to zero and miss out on being counted (for example, 0.00049 when rounded off to 3 decimals is 0)
- Many zero values influence a forecast
Some hints for choosing the right level of forecasting:
- At what level does sales history exhibit a pattern that could be forecast?
- Assuming that you are able to get good forecast accuracy at an aggregate level, is there a well-defined logic to disaggregate to a lower level? Can past sales always lead to the right proportional factors?
- Consider the supply planning aspect, too. If what you release to Supply Network Planning (SNP) is at SKU or distribution center (DC) level, how important is accuracy at the SKU or customer level?
The key choice while deciding the right forecasting level is the tradeoff between stability at higher levels versus approximation used due to disaggregation. This choice is often not a simple one. Let’s check out how a few companies address this issue.
Level Selection Examples
A large food goods company was in a fix when deciding at which level to forecast. The company used to have a concept of market SKU and system SKU for defining its products. Market SKU is the level at which the product is known to market. For example, a customer wants to buy a 100-gram glucose biscuit pack in a retail shop but actually buys a 120-gram glucose biscuit pack because of a special promotion. The product is planned and the company then analyzes the impact of various planned consumer promotions. System SKUs are the actual SKUs that are sold. This company’s product line includes biscuits and confectionaries.
The company has material codes in its ERP system at the system SKU level. However, it decides to do its forecasting at market SKU level as the products are steady at this level and have a long shelf life (as some of the system SKUs are available in market only for few months). That’s the level at which the marketing, sales, and planning teams are comfortable in planning.
One of the world’s largest lubricants manufacturers — with tens of thousands of customers — faces the question of whether to forecast at the DC level or at the ship-to party level. Forecasting at the ship-to level means:
- Good forecast accuracy at ship-to level but huge performance impact owing to the large number of SKU-ship-to combinations to be forecast
- Bloated demand at the DC level owing to aggregation of forecast errors (errors don’t cancel each other properly). The history at the detailed ship-to level is normally noisy and sporadic. However, at an aggregated level (DC) there is a smoother pattern. Most forecast models, when run at the detailed level where demand is sporadic, perform automatic smoothing and arrive at conservative forecasts. This happens without canceling out noise across multiple ship-tos. When these conservative forecasts are aggregated to a DC level, the volumes would be very high. If historical values are aggregated to the DC level, noises across ship-tos cancel each other out resulting in a smooth pattern.
Forecasting at the DC level means:
- Advantages of smooth historical pattern
- Good performance but with no clear disaggregation logic. Forecasts at the ship-to level can be skewed.
The final approach is to run the statistical forecast at the ship-to level to generate the forecast and re-run it at the DC level and disaggregate it to ship-to based on the forecast of the previous run.
Step 4. Clean the History
This step includes cleaning history from promotion, outliers, and cases of realignment. This is already covered in detail in one of my earlier articles, “10 History Cleaning Best Practices For Reliable Forecasting.”
Step 5. Understand Different Forecast Models Supported in APO
The first step of model selection is to understand different statistical forecast models supported in APO. Table 1 gives a brief explanation about all the statistical forecast models supported in APO as of version SCM 7.0 and where each of them is applicable. This table does not contain formulas for each model.

Table 1
Forecast models supported in APO
In most cases, as you start the model selection process you start with APO best-fit models. While the best-fit models do not ensure success, this can be a good starting point.
Best-Fit Models
The purpose of a best-fit model is to help businesses decide which model is best for them if they do not have any knowledge of a pattern of historical data. The best-fit model helps by:
- Dividing the historical periods into recent history and older history. For example, for the year 2011, the older period can be the 24 months from January 2009 to December 2010, and the recent period can be the last 12 months from January 2011 to December 2011.
- Running a set of forecasting models on an old historical period and creating an ex-post forecast for the recent history period.
- Comparing forecast values by different forecast strategies with actual sales (as actual sales for January 2011 to December 2011 are already known) and calculating forecast errors using the MAD method.
The strategy giving the lowest MAD is selected as the best model.
There are two best-fit models in APO are Model 56 (automatic model selection procedure 2) and Model 55 (automatic model selection procedure 1). Best-fit models do not guarantee that other APO models won’t provide better forecast accuracy. However, in most cases this is a good starting point. These models take a longer time to run as they do a lot of iterations, and, hence, they are not recommended for use in mass processing. Typically these models are not used post go-live in an APO project, but can be used during implementation model selection exercises.
Note
Did you know that APO offers model 99 for interfacing with external
forecasting tools? If you are not satisfied by the standard time series
models offered by APO, you can still use APO standard DP functionality,
but source statistical forecasts via an interface with an external
forecasting tool. One of world’s largest food companies adopted this
approach for certain product ranges.
Step 6. Short-List the Relevant Forecast Models and Build a Decision Tree
The next logical activity is to short-list the models that make sense for you — in other words, narrow down the best model candidates for your needs. Some of the APO models are elementary, such as copy history or manual forecast, and are not often used. Other models, including Croston, can be useful in special situations, such as when there are only intermittent demands or for a particular industry (e.g., spare parts). While there is no step-by-step process to short-list models, a quick analysis of historical sales gives an idea about which models make sense at a high level.
A decision tree is a good tool used by certain organizations for this exercise. Figures 1 and 2 are examples of how a company short-listed the models using this tool. The initial grouping was done based on whether the product demonstrated any seasonality, then whether it followed a linear trend.

Figure 1
Grouping statistical methods by seasonality and linear trends (method names shown)

Figure 2
Grouping statistical methods by seasonality and linear trends (method numbers shown)
Build a set of validation rules for identifying the best model: A model selected through simulation should pass a set of criteria before it is finalized as the most appropriate model for a particular product group. While a comparison of forecasts generated with actual sales is the most common validation approach, we recommend finalizing a set of validation criteria early enough in the project for final selection of a model.
Best-Fit Example
Here is an example from a real life case study. A large consumer goods company was implementing statistical forecasting for estimating demand for its finished products. Before going for full scale simulation with different statistical forecast models, the company developed a set of criteria for evaluating the short-listed models.
The model selected needed to score high in each of the following criteria:
- Visual similarity: The model should replicate a pattern similar to that of the product’s history (i.e., it is visually picking up the same trend or seasonality pattern when plotted)
- Ex-post forecast result: A forecast for a period for which history is known is done using all the short-listed models. The model should show minimum ex-post forecast variation.
- Consistency: One particular forecast model should show the best accuracy over other short-listed models consistently (i.e., month after month, or at least for most of the months)
- KPI validation: In this case the KPI for this project was to improve M+1 and M+2 forecast accuracy (i.e., forecast accuracy for the next month and the month after next). The selected model should provide better results than other short-listed models.
Step 7. Make the System Ready for Forecast Simulation
Preparing the system for simulation includes creating the following:
- InfoCube for cleaned history upload
- New planning area for simulation
- Simulation planning books, data views, and selection IDs
- Batch jobs for mass forecast runs for simulation
- Master forecast profiles with different forecast strategies
Simulation for model selection may need an InfoCube that differs from the one for daily sales data. This cube is used for loading cleaned history data. When the company is going to use statistical forecasting for the first time, typically cleaning is done in Excel files, and these cleaned files need to be uploaded in InfoCubes.
We recommend that you do the simulation exercise in a planning area different from your active planning area. This simulation planning area has related planning books and data views. While some companies use their active planning area for simulation, we do not recommend it. During model selection you may need a lot of extra key figures in the planning area to store different forecast values and ex-post forecast analysis that are not regularly used. Typically, a planner is supposed to use this planning area when there is a need to start forecasting for a product newly introduced into the scope of statistical forecasting, or the planner wants to try a new model for an old product as the selected model is not giving the required accuracy.
You also may need to set up batch jobs for a mass forecast run using different forecast strategies. Different forecast strategies are represented by different master forecast profiles that need to be created in a simulation environment.
Step 8. Perform Simulation Runs With Different Forecast Models and Result Recording
In this phase forecast runs are taken with different forecast models. You use cleaned history and forecast results for different product groups by different models. It is common to take forecast runs for the same product group using different historical periods (i.e., three forecast runs are taken for Product A using periods of two, two-and-a-half, and three years). These runs are typically used for ex-post forecast result analysis to see if the best-fit model picked up the same forecast strategy consistently for these three periods, or for which period the system is giving the best forecast accuracy compared with actual sales.
Simulation Example
There are several possible combinations for simulation runs. Here is an example of how a large global conglomerate managed the process. The history available is three years, the forecast horizon is 18 months, and the planning level is product group and country.
Activity 1: Perform a forecast simulation run with automatic model selection procedure 2 (model 56).In this step, Model 56 is run using a three-year historical horizon for each product group. Forecast errors and selected models are noted.
Activity 2: Perform forecast simulation runs with ex-post horizons. The company identified two sets of history-ex-post periods. In this case, out of an available three years of history, two sets were formed:
- Set 1: Two-year history (oneyear ex-post horizon)
- Set 2: Two-and-a-half-year history (six months ex-post horizon)
The company created forecast profiles for each combination of short-listed forecast models and horizon sets. Four models that supported seasonality were short-listed (models 31, 35, 41, and 56). Therefore, eight forecast profiles were created. It set up DP background jobs to run univariate forecasts using the above forecast profiles. It ran the DP jobs and stored the run results in different key figures as shown in Figure 3. The company then downloaded the run results into a spreadsheet for analysis (Figure 4).

Figure 3
Simulation planning book in which results of various runs with different models and horizons are viewed in different key figures
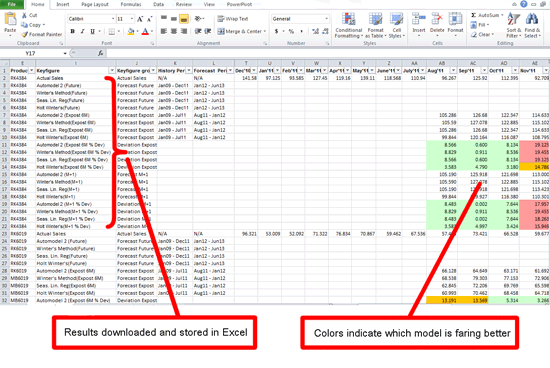
Figure 4
Master spreadsheet to record results and analyze different models
Activity 3: Perform forecast simulation runs with M+1 horizons. Since M+1 accuracy is one of the selection criteria, four sets of M+1 periods were identified:
- Set 1: Two-year, eight-month history (one month ex-post)
- Set 2: Two-year, nine-month history (one month ex-post)
- Set 3: Two-year, 10-month history (one month ex-post)
- Set 4: Two-year, 11-month history (one month ex-post)
The company created forecast profiles for each combination of short-listed forecast models and horizon sets. In this case, four models that supported seasonality were short listed (models 31, 35, 41, and 56), and 16 forecast profiles were created.
DP jobs were set up with these forecast profiles and forecast run results were saved in different key figures. For each product group, the results of different model runs were then downloaded into the master Excel spreadsheet and errors were calculated (Figure 4).
Excel formulas were written to color the cells with high forecast versus actual deviation to show which model fared better.
Step 9. Select the Best Model
The model is considered best for a product location combination once it meets all the validation criteria. However, in some cases it is difficult to find one particular model that consistently gives the best result. For example, seasonal linear regression gives good results in 60 percent of cases while doing the last six months ex-post forecast analysis, but the best-fit model consistently selects Holt Winters as the best forecast model for different historical periods. Further analysis is needed in these cases.
Once you zero in on one model, it is important to compare the forecast generated by the model with actual sales until go-live and at least for another three months post go-live to ensure that the model selection was appropriate. From a system perspective, the end deliverable of the model selection exercise is a set of master forecast profiles that can be used in the production environment.
Model selection is not a one-time exercise. If there is a change in the sales pattern of the product, then you need to repeat this exercise. The business can define a cut-off point for accuracy – an example is that anything below 70 percent is considered as poor accuracy and thus you need to revisit the models.
Step 10. Finalize the Consensus Demand Planning Process Around Statistical Forecasting And Disaggregation Logic
Organizations typically adopt a consensus planning process for arriving at the final demand plan with input taken from all relevant stakeholders. Then they agree on final forecast numbers.
Statistical forecast is one component of this final consensus demand plan. This helps in giving a good base forecast, and typically this is the first step of consensus planning process. Planners can modify the numbers if required based on market reality. Once these base forecast numbers are agreed upon, promotion is added to this to get the final forecast numbers. The consensus planning process can be quite complex in actual practice. Following is one such example.
Consensus Example
One of the leading consumer goods companies of India was doing an APO DP implementation for its tobacco and food business. The company had a complex sales hierarchy in which the country was divided into four regions. Each region is made up of a set of districts, each district has a set of branch sales offices, and finally each branch has a set of areas and territories. An area executive (AE) takes care of sales of each area, and an area manager (AM) has overall responsibility of an area. Branch managers (BM), district managers (DM), and regional sales managers look after particular branches, districts, and regions.
The first step of the DP process the company adopted was a statistical forecast run at the product group level based on three years of history. This forecast is copied to another key figure. AEs do modifications based on their knowledge of market reality. This forecast goes to AMs, who also can do manual adjustments. Finally, the AM and AE come up with a consensus estimate. BMs also look at stat forecast figures and make their own estimate as a parallel process that is rolled up to the DM level, and, finally, the BM and DM come up with a consensus estimate.
Disaggregation Example
Another challenge for the consensus planning process is right disaggregation. A consensus forecast needs to be disaggregated from the product or location group where forecasting is done to the right product and right location. In addition to this hierarchical-based disaggregation, you may need time-based disaggregation. The forecast might need to be disaggregated from months to weeks or weeks to days. Sometimes businesses can have specific requirements that are tricky. Here is one such example.
A large tobacco company trying to disaggregate its forecast from the product group level to the individual product level faced several challenges. The company had a set of steady product groups with a long shelf life. However, at a particular product level, its products had a short life cycle of three to four months with the frequent introduction of new products with new blends to address regulatory requirements for packaging or changes in tax structure. The company also frequently introduced promotional products that were active for a few weeks.
The company wanted to have a set of complex disaggregation results as follows:
- Base forecast should only be disaggregated among active products that are not promotional products
- Disaggregation should be always based on last month’s historical sales proportion
- If the planner manually changes the proportion in a particular time period, this disaggregation proportion should be obeyed during the next forecast run (i.e., it should not be overwritten based on last month’s historical proportion)
This diasaggregation logic was built with a set of complex macros and needed rigorous testing. While rolling out this statistical forecasting project globally, the company had to develop several country specific macros as well because a few countries wanted small variations in this logic based on the way they do business.
Step 11. Complete Configuration of the APO DP System
Once the forecast model is selected, the next step is to make relevant settings from the system side in the production system that planners use post go-live. This could include:
- New DP area for simulation.
- New InfoCube for loading cleaned history in simulation planning area.
- New consensus DP area, planning book, and data views. If the company is already using DP and now wants to introduce statistical forecasting, modification or updates in existing DP planning areas, books, and data views may be required.
- New macros (copy macros for copying stat forecast and forecast disaggregation).
- Changes to authorizations and roles.
- Creation of new forecast profiles.
- Creation of new DP selections.
- New DP batch jobs (for example new copy job, new job for stat forecast run, new jobs for consensus planning calculations).
Some of these activities (e.g., the first six activities in the above list) need to be created in a development environment and then transported to the quality and production environments. Some need to be done directly in the production environment as they are either not transportable (batch jobs) or they are simpler to re-create than transporting from development (for example, creating master forecast profiles).
Note
When setting up forecast profiles, always use the number of periods for
defining history and forecast horizons instead of hard coding start and
end dates. This way the horizons automatically roll as you move into
future periods.
Step 12. Conduct User Acceptance Testing and Training
There are two levels of user acceptance testing (UAT) for a statistical forecasting project:
- UAT 1: Acceptance of forecast models and stat forecast result by users
- UAT 2: Acceptance of the new consensus planning, disaggregation logic, and planning books
While UAT1 should ideally happen after step 9, when the best forecast models are finalized, in this phase you explain how the relevant forecast model works to a wide group of demand planners who possibly were not part of the project core team. In the second phase, planners also sign off on the new consensus planning process and disaggregation logic. For a successful UAT 2, it is important that all possible consensus planning or disaggregation scenarios are part of UAT test script.
Training is a mandatory activity prior to UAT. Users are trained on different forecast models, how each of them works, the consensus planning process, and disaggregation.
Although training is covered in this step, the activity starts much before UAT. Training is needed in different phases of the project, for example:
- The core team need to be trained in different statistical forecast models before a forecast model selection exercise starts
- Users need to be trained in particular stat forecasting tools relevant for the company
- A steering committee needs to be trained on high-level capabilities of the forecasting tools
Step 13. Perform Cut-Over and Data Migration
A number of cut-over and data migration activities may be required before a statistical forecasting project can go live. It is important to prepare a detailed cut-over checklist early. This list can differ depending on whether the company is going for APO DP along with statistical forecasting or the company already has APO DP in place but is implementing statistical forecasting for the first time. A typical list of such cut-over activities can include:
- Load cleaned history data in APO system
- Load promotion data in APO system
- Upload all manual planning inputs (e.g., a planner’s inputs, A sales rep’s inputs) from the existing planning system to APO DP.
- Conduct a dummy run of all existing batch jobs for statistical forecasting and consensus planning to check whether the time taken for these jobs fits into the existing planning calendar.
- Perform final testing of all authorization profiles (to test whether planners can access required planning books, data views, and selection IDs without any problem).
Step 14. Begin Go-Live and Ongoing Monitoring of Forecast Accuracy
Once the statistical forecast project goes live, it is important to see whether it is really producing the intended benefits. As improving forecast accuracy is one of the common KPIs for such a project, forecast accuracy need to be measured post go-live on a regular basis, and actions need to be taken as soon as this falls below a defined threshold. For example if the statistical forecast accuracy falls below 80 percent for a certain product category, you do a thorough investigation in terms of reviewing forecasting models. Ongoing monitoring can also include:
- Model selection for new products that come under the scope of forecasting post go-live
- Watching for changes in existing forecast disaggregation logic that require changes in the macro
- Maintenance of valid active Characteristic Value Combinations (CVCs) and deletion of old CVCs.
- Creation of new batch jobs and modification of existing jobs.
The success of statistical forecasting projects depends on how effective this ongoing monitoring process is. We have seen companies that did not review forecast models that were in place for as long as three years. No wonder their current forecast accuracy is not as desired.
Step 15. Maintain an Issue Database
Rajesh Ray
Rajesh Ray currently leads the SAP SCM product area at IBM Global Business Services. He has worked with SAP SE and SAP India prior to joining IBM. He is the author of two books on ERP and retail supply chain published by McGraw-Hill, and has contributed more than 52 articles in 16 international journals. Rajesh is a frequent speaker at different SCM forums and is an honorary member of the CII Logistics Council, APICS India chapter and the SCOR Society.
You may contact the author at rajesray@in.ibm.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.

Sangeeth K. Parvatam
Sangeeth K Parvatam is a senior SCM consultant at IBM GBS and is a subject matter expert of APO core modules. With strong technical background, he has designed several custom developments in APO which are now offered as APO Standard functionality. He has implemented APO across various industries including Consumer packed goods, FMCG, Oil & Gas, Metals & Mining. He specializes in designing Statistical Forecasting process and implementing it from data analysis stage till go-live.
You may contact the author at Sangeeth.parvatam@in.ibm.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




