SAP BW 3.x does not allow you to run two delta loads back to back. Learn a workaround involving DataStore objects and a pseudo delta load that allows you to do this. You can use this functionality to improve system performance in processing high data volumes when implementing complex business logic.
Key Concept
An intelligent lookup table is a DataStore object with data required as a lookup when processing high data volumes. An intelligent lookup table can optimize data processing in a multi-layer business warehouse setup. Usually it is a subset of a large data set containing only the records you need for a particular data load. This subset contains only relevant details corresponding to business logic related to your project. An example of an intelligent lookup table is a DataStore object containing accounting document numbers mapped to vendor codes and purchase order (PO) numbers. During each delta load, this DataStore object contains only those records that relate to the data set that you’re currently processing.
A purchasing group in a multi-billion dollar corporation wanted to improve its operational reporting capabilities by daily updates of purchasing performance indicators and management dashboards. The operational purchasing group sources and purchases all non-production goods and services including external resources and consultancy. I helped to implement a multi-layer BW data model to fulfill its needs using intelligent lookup tables and a pseudo delta approach.
This setup provides a capability to implement complex business logic when moving line items to the second level. At the same time, it substantially speeds up data processing time — 30 million transaction lines used to run for three days in the old setup, but with the intelligent lookup tables it took 26 hours.
The project requirements included complex filtering logic for invoices and purchase orders. The project team and I used a multi-layered BW setup to ensure the solution is scalable and reusable. First, all documents are loaded to the first level because projects other than this one might use them. Second-level DataStore objects contain only project-related documents with certain business logic applied. On the third level, the BW system aggregates data in the reporting InfoCubes.
For the purposes of operational purchasing analysis, the project team had to account for only a fraction of the original invoices extracted from SAP R/3. Only some invoices pertained to the operational purchasing group reporting. Secondly, the team had to update invoice line items derived from Financial Accounting (FI) in R/3 with extra attributes such as vendor codes and expense G/L accounts relevant for this project. The team could derive attributes either from FI invoices or corresponding Materials Management (MM) purchase order (PO) line items.
The invoice filter had to comply with the following business rules:
- Remove employee and intercompany settlements
- Keep only line items with project relevant G/L accounts
- If the invoice has the goods received/ invoice received status, then retrieve the corresponding G/L account from the relevant PO item
- Keep only line items with project-relevant document types
- Keep only line items with project-relevant posting keys
When taking the invoice line item to the next level (only those lines that qualify for the operational purchasing group), the project team must enhance it with the following attributes:
- Retrieve the vendor code from the header of the same document
- Classify the vendor into recommended or non-recommended categories based on G/L account, posting key, and master data list of recommended vendors
- Assign country tier, business group, and region codes to invoice line items
The benefits of this approach include improved data load performance, scalability (easy modifications to data models and introduction of new capabilities), and the ability of multiple projects to share first-level DataStore objects and apply unique project-related filters and business logic when moving data to the second level. I implemented this technique for R/3 4.6 and BW 3.0. You can use it with other software releases as well, such as SAP NetWeaver 2004 and 2004s.
Data Processing Challenges
To implement this logic, you have to process vast data volumes, especially during history loads. Properly dealing with huge data volumes was very critical in this project. The company loaded four million General Ledger Accounting (FI-GL) records per day (including modified documents), or about 30 million records per historical period. Loading history becomes a challenging task as such vast volumes require days of processing time per period loaded. Extraction from the source may take days of loading, but also data transformation and transfer to the second level may need a lot of system resources and processing time.
From a technical point of view in this particular case, the project team needed to look up two transactional values when moving invoices to the second level: a vendor code for invoice line items and a G/L account for purchase order line items. The content of these lookup tables consists of millions of records, which creates extra complexity during data processing and negatively affects performance.
The Solution: Intelligent Lookup Tables
The project team decided to split the data loading processes into phases in which it filled lookup tables first and then continued with transactional uploads as shown in Figure 1. In the first step, the team loaded the data to the first-level DataStore object from the source system. In the second step, it filled the lookup tables with delta records. In the third step, it moved the same delta from the first-level DataStore object to the second level. And finally, it moved the delta records received in the second DataStore object to the InfoCube.

Figure 1
Back-to-back delta processing steps
However, BW 3.x does not permit you to use the same delta records in two data loads one after another: first when filling lookup tables and then in the data processing to the second level. That is why the project team decided to use a pseudo delta approach. SAP NetWeaver 2004s offers a new capability of running the same delta processing subsequent to multiple data targets. Therefore, in the applications developed for this release, you may implement the consequent delta run approach instead of using the pseudo delta scenario described here.
In the configuration where you use the Delta — Full — Delta update approach it is practical to automate loads using the Data Load Date field in the first- level DataStore object. Based on this field, the team implemented a pseudo delta approach that used full loads for picking up deltas from the first-level DataStore object. This provides better control over data loads and data refreshes and at the same time fully automates upload processes.
Use Intelligent Lookup DataStore Objects
As you can see in Figure 2, data comes from FI or MM to the first-level DataStore object. Then it moves to the second-level DataStore object, where BW applies project-relevant business logic. And finally, BW transfers data to the InfoCubes.
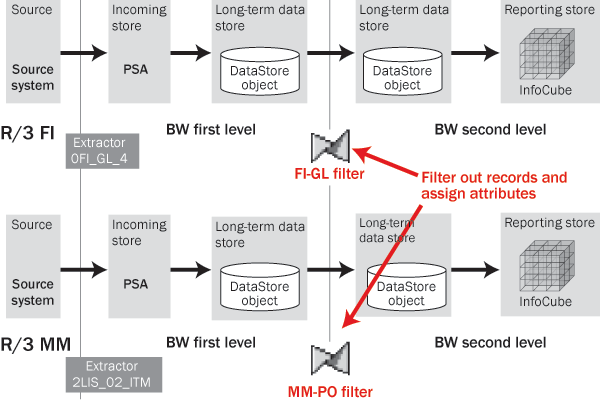
Figure 2
DataStore object update rules define filters and attribute assignments
When you begin implementing this approach, analyze the first-level DataStore object (in this case ZFIGL_02) and identify fields (InfoObjects) to use in the lookup DataStore object. Next, create this DataStore object (in this case ZFIGL_LU) by copying the first-level DataStore object and leaving only those fields (InfoObjects) to use in the lookup DataStore object. To create a DataStore object, right-click on the InfoArea used in your project and select Create DataStore Object. Next, copy this DataStore object as Figure 3 shows. In this example, I created a new DataStore object (ZFIGL_LU) and specified the name of the original DataStore object (ZFIGL_02) in the Copy from field. The fields to use in the lookup DataStore object vary by project.
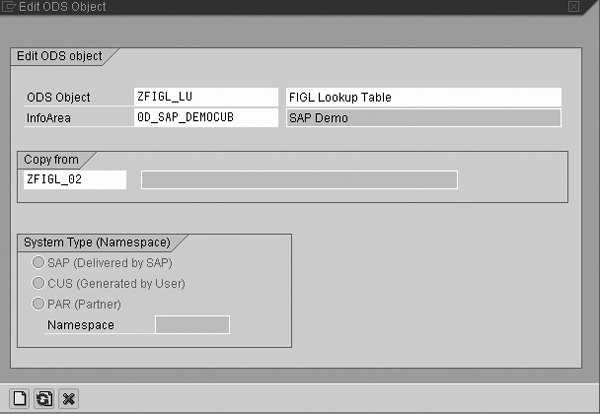
Figure 3
Create DataStore object ZFIGL_LU
Next, create update rules of the lookup DataStore object by specifying the original DataStore object as an InfoSource (ZFIGL_02). To create update rules, right-click on the DataStore object and select Create update rules. Specify the InfoObject mapping and filtering logic needed to populate the lookup table. Here you may want to filter out records that are not in the project-relevant vendor or G/L account range.
The lookup tables for daily delta updates should contain only records relevant for the records in the delta. This approach allows you to reduce the size of lookup tables from millions of records to hundreds of thousands and therefore improve performance.
Use the same approach for designing a lookup table for POs (in this case ZPOORD). When filling in a lookup table with PO line items I recommend that you keep only records with project-relevant G/L accounts. This means in the DataStore object update rules you want to set up a filter to check if the G/L account is in the list of project-relevant accounts. In the tested environment this approach filters out two-thirds of the original two million records and ensures that if the PO is found in the lookup table it contains a project- valid G/L account. This G/L account further on would replace the goods received G/L account in the original invoice line item.
You can use the code in Figure 4 in the start routine of the update rules for the PO lookup DataStore object (in this case ZPOORD). If you need assistance accessing the start routine, read the “How to Get to the Update Rules” download in the Downloads section of November/December 2006 BW Expert. The PO lookup DataStore object ensures that only those PO line items are kept in the DataStore object that contain project-relevant G/L accounts listed in the ZGLACT characteristic.
LOOP AT DATA_PACKAGE.
READ TABLE itab_glac WITH TABLE KEY
/bic/zglact = DATA_PACKAGE-/BIC/YSAKTO.
IF sy-subrc NE 0.
DELETE DATA_PACKAGE.
ENDIF.
ENDLOOP.
|
| Figure 4 |
Script to use in the start routine of ZPOORD DataStore object update rules |
When filling in a lookup table for vendor codes, the team only needs to keep four types of line items that relate to the solution:
- Vendor codes that do not relate to the employee or company and vendor codes that are not blank
- Posting keys that relate to the project expense (range of expense-related posting keys defined by R/3 configuration team from 22 to 33)
- Document types that relate to the project
- G/L accounts that relate to the project
After you apply these filtering rules, by including filtering logic in the update rules start routines, less than 2% of the original record volume remains. This makes the lookup feasible and realistic in the case of processing tens of millions of records. Figure 5 shows the multi-layer data processing environment.
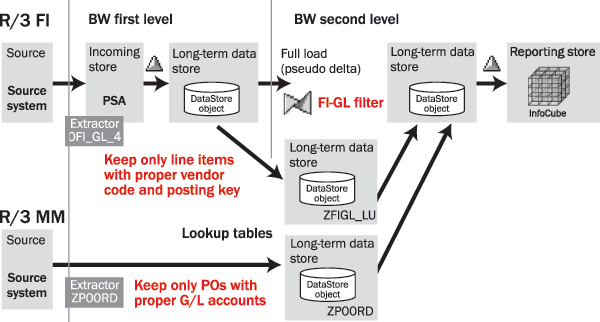
Figure 5
Intelligent lookup DataStore objects in a multi-layer data processing
After populating the lookup tables (DataStore objects), the next step is to upload the second- level DataStore object with records containing only project-relevant line items. In the update rules, apply business logic for each line item defined by project requirements.
You can use the ABAP code in Figure 6 in the update rules start routine of the second- level DataStore object. Use this code in the start routine of the second-level DataStore object (in this case ZFIGL_03). To get there, double-click on the Update Rules and then click on Change Start Routine. This algorithm searches for proper vendor codes in the lookup DataStore object, using an internal hashed table pkey22_33 with a unique table key.
TYPES:
BEGIN OF pkey22_33_struct,
ac_doc_no like /BIC/CS8ZFIGL_02-ac_doc_no,
comp_code like /BIC/CS8ZFIGL_02-comp_code,
fiscper like /BIC/CS8ZFIGL_02-fiscper,
gl_account like /BIC/CS8ZFIGL_02-gl_account,
vendor like /BIC/CS8ZFIGL_02-vendor,
post_key like /BIC/CS8ZFIGL_02-post_key,
END OF pkey22_33_struct,
…
DATA:
pkey22_33 TYPE HASHED TABLE OF pkey22_33_struct WITH UNIQUE KEY
ac_doc_no comp_code fiscper WITH HEADER LINE.
…
IF pkey22_33[] IS INITIAL.
SELECT ac_doc_no comp_code fiscper gl_account vendor post_key
INTO TABLE pkey22_33
FROM /bic/azfigl_lu00.
ENDIF.
…
LOOP AT DATA_PACKAGE.
READ TABLE pkey22_33 WITH TABLE KEY
ac_doc_no = DATA_PACKAGE-ac_doc_no
comp_code = DATA_PACKAGE-comp_code
fiscper = DATA_PACKAGE-fiscper.
IF sy-subrc = 0.
DATA_PACKAGE- vendor = pkey22_33-vendor.
…
ENDIF. MODIFY DATA_PACKAGE.
ENDLOOP.
|
| Figure 6 |
Use this code in the start routine of the second-level DataStore object update rules to look up a vendor using a unique combination of accounting document number, company code, and fiscal period as a search key |
Note
In the production environment, implementing the intelligent lookup DataStore objects has reduced data processing time by 2.5 times in the business case described earlier.
Automate Delta Loads Using Pseudo Deltas
It is a challenging task to properly manage delta updates in a multi-layer environment with multiple data targets. The complexity lies in moving deltas to the lookup tables, and later moving the same delta to the second-level DataStore object (project-related line items). You also can use the first-level DataStore object in other projects, which makes the task of managing original deltas quite complex.
To properly manage deltas between DataStore objects, I suggest using a pseudo delta approach. The concept is based on adding a Dataload Date field to the first-level DataStore object. Add an extra InfoObject called ZDATALOAD to the list of first-level DataStore object data fields (ZDATALOAD in Figure 7). Double-click on the DataStore object, right-click on Data Fields, and then choose Insert InfoObjects.

Figure 7
Create an extra InfoObject called ZDATALOAD
Double-click on the update rules of the first-level DataStore object. Populate the Dataload Date field with the system date in the update rules at the data processing time (Figure 8).

Figure 8
Populate the Dataload Date field with the system date at the data processing time
By setting the Dataload Date in the InfoPackage selections you can manage loads to the second-level DataStore object with full requests. This approach allows you to select records loaded on a certain date to the first-level DataStore object (Figure 9). Usually you would select yesterday’s records to pick up the last daily delta records unless the daily delta process chain was abnormally interrupted.
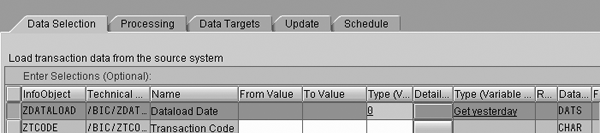
Figure 9
Select records loaded on a certain date to the first-level DataStore object
The variable set in Figure 9 selects transaction lines with the Dataload Date set to yesterday — that is, all delta records loaded to DataStore object yesterday. You must use the pseudo delta scenario of consequent loads to ensure optimal data processing performance: populating an intelligent lookup table with delta records, and then further processing of delta records from the first to the second level using lookup data.
The pseudo delta approach allows you to easily take a DataStore object or an InfoCube back to an earlier state by deleting full requests and refreshing them if needed. You may need this if you encounter problems with delta loads to further targets, especially in the cases in which one source DataStore object is feeding multiple data targets. Most importantly, this approach allows you to load pseudo deltas to multiple data targets at different times. This is especially important in the Delta — Full — Delta scenario.
Sergei Peleshuk
Sergei Peleshuk has more than 15 years of experience implementing BI technologies for global clients in retail, distribution, fast-moving consumer goods (FMCG), oil, and gas industries. He has helped clients to design robust BI reporting and planning capabilities, leading them through all project phases: from analysis of requirements to building BI roadmaps, technical architecture, and efficient BI teams. Sergei is an expert in modern BI tools and technologies available on the market, including SAP Business Warehouse (SAP BW), SAP HANA, BusinessObjects, and SAP Lumira. Sergei maintains a business intelligence portal at www.biportal.org.
Sergei will be presenting at the upcoming SAPinsider HANA 2017 conference, June 14-16, 2017, in Amsterdam. For information on the event, click
here.
You may contact the author at peleshuk@biportal.org.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




