
Navigate the Complexities of Big Data with SAP Vora
In today’s world of distributed and near endless big data, IT faces a wealth of new challenges. Data scientists must find ways to work with multiple data sets pulled from a myriad of sources to derive conclusions and reach actionable business decisions.
SAP Vora, an in-memory query engine that plugs into the Apache Spark execution framework, helps IT navigate the challenges of big data by providing enriched, interactive analytics with data stored in Hadoop. Read this chat transcript to learn more about how SAP Vora helps democratize data access in order to help you make better business decisions. Attend to get answers to questions such as:
- What is SAP Vora?
- What is the difference between SAP HANA and SAP Vora?
- What are some use cases for SAP Vora?
- What is the roadmap of SAP Vora with respect to Secure Copy Protocol (SCP)?
- How would you deploy SAP Vora in a container-type environment?
If you haven’t already, subscribe to SAPinsider Online for free today!
Explore related questions
Matthew Shea: Hello, and welcome to today’s chat on SAP Vora and big data. I am excited to be joined by a team of experts from Lenovo, SAP, and SUSE.
Al Kalafian is an SAP Infrastructure Architect and the Team Lead for the Lenovo SAP Center of Competence in North America. Al joined IBM in 1981, and he has over 20 years of experience with SAP applications. He has deep technical experience with all SAP applications that are running on the Intel platform and SAP appliance offerings, such as SAP Business Warehouse Accelerator and SAP HANA. Al has several certifications, including SAP Certified Basis Consultant, SAP Certified Installer, IBM Certified Technical Professional, IBM System x hardware, Microsoft Windows, and Red Hat Linux.
José Betancourt is a Senior Architect at SUSE, where he works with global original equipment manufacturer (OEM) partners to understand their business and technical requirements and make them successful with SUSE. His focus area is SUSE Linux Enterprise for SAP applications and SUSE Linux Enterprise Live Patching. You can reach him at jose.betancourt@suse.com.
Walter Muntzenberger has over 30 years of experience working with data. His expertise is in all aspects of enterprise data architecture, analytic and operational applications, and related use cases across multiple verticals. He is a Vice President in the Global HANA Center of Excellence at SAP, and Walt’s team works primarily with customers worldwide helping them architect their big data vision and roadmap to run their businesses faster, simpler, and smarter.
Paul Hearmon is a platform architect in the Global HANA Center of Excellence at SAP. He has broad experience in business intelligence (BI) and enterprise information management (EIM) platform architectures, big data, security, and deployment. He is excited to answer your infrastructure and big data questions today.
Walter Muntzenberger: This is Walt with SAP. I’m happy to be able to respond to some of these great questions.
Comment From Guest: I have never heard of SAP Vora before. Please take a few minutes to explain what it is.
akalafian: SAP Vora is an in-memory solution from SAP designed to add business logic and functionality to big data residing in large Hadoop file systems.
Walter Muntzenberger: In a way think of SAP Vora as sitting between the crystal-clear, pure water of the business — structured, relational, accessed through SQL (SAP HANA plays a role here) — and the murky depths of the unstructured big data ocean. I view SAP Vora as sort of the desalination plant, allowing the data to be processed and flow in both directions between both sources.
Comment From Joseph: Help me understand the difference between SAP HANA and SAP Vora.
Walter Muntzenberger: First, I’ll discuss where the two products are similar. Both are leveraging in-memory, columnar compression techniques. They also have many of the same calculation engine capabilities. But SAP Vora is designed for web scale and is not designed to be a persistence layer. SAP Vora reads data from your object store, creates a memory image of that data for an analytic purpose, and combines it with other data. SAP HANA is meant not just as an analytic store, but also as an online transaction processing (OLTP) repository. It combines online analytical processing (OLAP)/OLTP into a single version of data.
Comment From Jay: How can we gain insight into large volumes of operational and contextual data taken from enterprise applications, data warehouses, data lakes, and Internet of Things (IoT) sensors?
Walter Muntzenberger: As we all know, SAP HANA is a very high performance, simple in-memory solution, but as data scales it cannot be the central location for all volumes of big data and all different types of calculation workloads. So SAP Vora can be used as another calculation layer to work side by side with SAP HANA directly against big data and unstructured data.
Comment From Syam: To fetch the cold data from Hadoop, SAP HANA smart data access is also available. Why again would I need SAP HANA and SAP Vora?
Walter Muntzenberger: SAP HANA smart data access is still viable functionality from SAP HANA, but it relies on being able to push optimization to the source. Federation becomes difficult when data shipment becomes excessive. So SAP Vora can be used to provide scalable scanning of large volumes of data in Hadoop Distributed File System (HDFS) and Amazon’s Simple Storage Service (S3) where SAP HANA smart data access isn’t appropriate.
Comment From Daisy: Our manufacturing firm client wants to do analytics on test data generated. I understand SAP Vora can run on Hadoop. But if we prefer to keep out data in SAP BW itself, can SAP Vora play a role to increase the performance? We have the test data in SAP BW now.
Paul Hearmon: Technically, SAP Vora runs on Kubernetes clusters. It consumes data from sources including Hadoop. Should you choose not to use SAP BW for these types of data, you can use SAP Vora to increase the performance of queries from these data sources.
Comment From Prabhu: What is the roadmap of SAP Vora with respect to Secure Copy Protocol (SCP)?
Walter Muntzenberger: For SAP Vora, the move is to containerization (Docker and K8S). SAP Vora 2.0 runs independently of Spark. So the release of the containerized version will first be available as an infrastructure-as-a-service (IaaS) solution and then later in 2018 will be able to run in Secure Shell (SCP).
Comment From Nick: How would you deploy SAP Vora in a container-type environment?
Walter Muntzenberger: Nick, see the diagram below. Note that the nodes of SAP Vora are in Docker containers managed by Kubernetes. Containerized SAP VORA (2.0) doesn’t run directly on the Hadoop/Spark nodes.
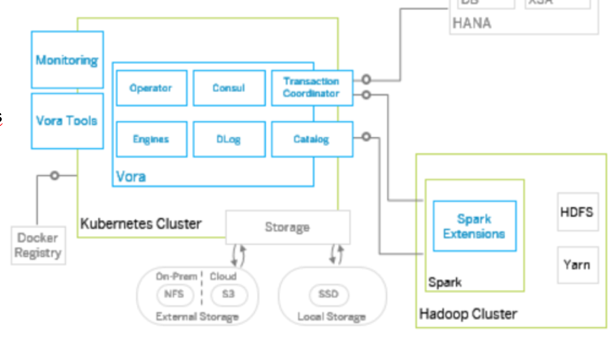
Docker is the world’s leading software container platform. Enterprises use Docker to build agile software delivery pipelines to ship new features faster, more securely, and with confidence for both Linux and Windows Server apps. When an organization uses containers, everything required to make a piece of software run is packaged into isolated containers. Docker automates the repetitive tasks of setting up and configuring production environments, and dependencies are pulled as neatly packaged Docker images. A container image is a lightweight, standalone, executable package of a piece of software that includes everything needed to run it: code, runtime, system tools, system libraries, settings. Available for both Linux- and Windows-based apps, containerized software will always run the same, regardless of the environment. Containers isolate software from its surroundings (for example, differences between development and staging environments) and help reduce conflicts between teams running different software on the same infrastructure. SAP Vora is delivered as Docker images (dqp, thriftserver, catalog, monitoring, and so on). This is different from the previous way of install since with SAP Vora 2.0, the installer builds these Docker images and uses Kubernetes to manage them.
Jose Betancourt: SAP Vora can be containerized leveraging Docker container technology. SUSE offers Docker containers with the traditional operating system (SUSE Linux Enterprise Server), but more interesting we have a container-as-a-service (CaaS) platform where SAP Vora 2.0 was released.
Mind you, the CaaS platform 2.0 is already out.
Comment From Syam: Can we do SAP HANA Vora things using SAP HANA smart data access? What are the limitations?
Paul Hearmon: SAP HANA can federate queries out to external sources, including SAP Vora, via SAP HANA smart data access. Limitations would be as per any SAP HANA smart data access source regarding retrieving suitable volumes of data.
Comment From Dustin: Can I get matching OS support offering for the SAP HANA and SAP Vora components?
Jose Betancourt: Yes. SUSE can provide priority support for “standard” SUSE Linux Enterprise Server (for SAP Vora) and SUSE Linux Enterprise Server for SAP Applications (for SAP HANA).
Comment From Jason: What is the relationship between SAP Vora and SAP Data Hub?
Walter Muntzenberger: SAP Data Hub is a new product from SAP that is designed to allow more efficient data management and wrangling of big data and systems of record (SAP S4/HANA or SAP ERP Central Component [ECC]). The key to this is building data flows or pipelines to allow easy access, profiling, transformation, and orchestration. SAP Vora is included in SAP Data Hub as the pipeline engine. Therefore, SAP Data Hub also takes full advantage of a containerized architecture.
Comment From Praveen: Can SAP Vora be leveraged between different SAP databases (SAP HANA, Oracle, SAP MaxDB) and big data solutions? If so, what value does it provide?
Paul Hearmon: I’m assuming you’re referring to the relational databases that sit under SAP ECC.
SAP Vora is primarily designed to consume data from big data sources. Analytical data/workloads are serviced by the relational engine, but increasingly, we’re seeing more IoT workloads (streaming ingest and granulation) being supported by the time series engine.
Comment From Marie: How do you architect (from an OS and applications perspective) for high availability (HA) in an SAP Vora/SAP HANA environment?
Al Kalafian: So this is actually two questions. SAP HANA in a single-server environment can achieve HA by using a combination of SAP HANA Replication and SUSE Linux Clustering. SAP HANA in a clustered environment uses hot spare technology to have a spare node take over in the event that a working node fails. Another option for SAP HANA in a clustered environment is to use SUSE HA for the entire cluster so that the entire cluster can fail over to a secondary cluster.
As for SAP Vora, SAP Vora sits on top of a Hadoop cluster that has HA capabilities built into the technology so that a Hadoop node is not a single point of failure.
Jose Betancourt: There is additional documentation on cost and performance optimized HA scenarios for SAP HANA on SUSE Linux Enterprise Server for SAP Applications at: https://www.suse.com/products/sles-for-sap/
Look for the SAP HANA SR Performance and Cost Optimized white papers. They provide detailed setup configurations.
Al Kalafian: Let me provide a little more detail on SAP HANA in a single-server environment. All that is required is to have a secondary SAP HANA server that is identical to the primary one. The primary SAP HANA server will use SAP HANA replication to ensure that any data changed and persisted in the primary server is sent to the secondary one. Sync and async processes are supported here. Using only SAP HANA replication, the failover is manual. To make the failover automatic, you could also implement SUSE HA clustering in this environment.
Comment From Ben: What is time-series data? Do I need a time-series database?
Walter Muntzenberger: To define time-series data, think of IoT. I have a timestamp as well as a measurement and the ID of the device. This data is thin, but it has lots of records. When we analyze time-series data, we are generally trying to sequence the data, make the data equidistant (so aggregate the data to every 15 minutes, for instance). But then you also have to handle missing data (maybe add some smoothing) and deal with late-arriving data. You also need the ability to do this on the fly.
Time-series analytics then uses algorithms to do things such as forecasting (triple exponential smoothing, for instance).
Or use machine learning to further refine and predict the future.
Comment From Linda: What is Google Kubernetes? Where can I learn more about it?
Walter Muntzenberger: Kubernetes is an open source platform designed to automate deploying, scaling, and operating application containers.
With Kubernetes, you are able to deploy applications quickly and predictably, scale your applications on the fly, roll out new features seamlessly, and limit hardware use to required resources only.
Kubernetes is portable, extensible and self-healing. Hence, it is perfectly suitable for private, public, and hybrid cloud deployments. The self-healing capabilities enable auto-placement, auto-restart, auto-replication, and auto-scaling.
You can learn more at these sites:
- https://kubernetes.io/docs/home/
- https://kubernetesbyexample.com/
Comment From Bryce: How is the MapR filesystem different from HDFS?
Paul Hearmon: There are many differences between the two, and a fairly comprehensive comparison is provided here. Essentially, traditional HDFS is written in Java (therefore, performance may not be as fast as native C file systems) and is immutable. MapR Data Technologies’ philosophy is to rework the parts of Hadoop it sees are lacking to provide more enterprise-class capabilities, whereas the other Hadoop vendors’ philosophies are to build around the open source core.
Comment From Alex: Does SAP Vora provide tools for end users to consume data from a lake, including sharing or publishing a data model, or is there another way to achieve this with SAP tools?
Paul Hearmon: True end-user capabilities are provided by BI tools such as SAP Lumira.
Comment From Josh: What is Apache Spark?
Walter Muntzenberger: Apache Spark is a fast general engine for large-scale data processing. It is an open source project and commercialized by Databricks. Think of it as an in-memory extraction of data from Hadoop, without the complexity of MapReduce and operating at much faster speeds. SAP Vora then takes it up another notch in terms of performance, but also integration and simplicity.
For more information go to https://spark.apache.org/.
Comment From Andrew: Is SAP Vora the only way to integrate SAP HANA and Hadoop?
Paul Hearmon: SAP Data Services provides a way to perform extract, transfer, load (ETL) from Hadoop to SAP HANA.
SAP HANA smart data access via the Spark Controller provides federation across any data in HDFS accessible by Spark.
SAP HANA smart data access via SAP Vora provides a way to accelerate targeted data in HDFS by loading subsets of HDFS data and then querying it via SAP HANA smart data access federation.
SAP Data Hub will provide a rich, comprehensive pipeline drawing data from sources such as Hadoop (via native Spark jobs).
Comment From Kamlesh: What is an example use case for SAP Vora (please state the input type, computation, and output type)?
Walter Muntzenberger: SAP Vora has built-in time-series, graph, and document storage engines. So some of the use cases might be analyzing IoT sensor data, running machine learning to understand patterns, reacting to those patterns, predicting patterns, doing asset maintenance, and forecasting.
So lambda-type patterns are well suited for SAP Vora and Spark to be part of the “serving” layer in those architectures.
Centerpoint Energy was an early adopter of SAP Vora.
Other use cases would be point-of-sale (POS) data in retail, prescription data in pharmacies, and global track and trace in consumer-packaged goods (CPG) and distribution.
Comment From Kamlesh: Does SAP Vora support SAP BW as a data source? If not, is there a way to convert SAP BW data in the form that is supported by SAP Vora?
Paul Hearmon: There is no native, direct connectivity between SAP Vora and SAP BW. However, SAP Data Hub provides pipeline capabilities that can connect SAP BW, SAP Vora, and SAP HANA.
Comment From Kamlesh: How does SAP Vora leverage Spark, or does it?
Paul Hearmon: In a way, the question should be how does Spark leverage SAP Vora? Imagine you’re a data scientist working within the Spark shell accessing data via the Hive Metastore and you wish to access data residing within SAP HANA or SAP Vora directly. SAP Vora and SAP HANA tables appear as Spark data sources (in a similar way, for example, that Apache Cassandra appears as a Spark data source), allowing you to easily combine native HDFS data with real-time data held in SAP Vora or SAP HANA without the need for replication.
Comment From Kamlesh: Is SAP Vora just a compute engine, or can it serve data to BI tools sitting on top (such as Tableau) via Java Database Connectivity (JDBC)?
Paul Hearmon: Yes, SAP Vora can serve data to BI tools sitting on top (such as Tableau) via JDBC, although currently only SAP Lumira is officially supported.
However, we see the power of using SAP Vora — within SAP Data Hub — as an immensely powerful way to combine data from multiple sources. Suppose you have a result set from Hadoop, a result set from SAP BW, and a result set from SAP HANA. Where exactly would you combine them?
Comment From Allen: How can I explore this further? Where do I get started on an SAP Vora project?
Walter Muntzenberger: First, you can find more information at https://www.sap.com/products/hana-vora-hadoop.html. At this SAP site you can view training videos and take a product tour. Additionally, SAP has built a partnership with Lenovo, SUSE, and MapR; you can actually build a solution in the Lenovo demo center in Raleigh, North Carolina.
Finally, you can talk directly to my team about doing a proof of concept (POC) or pilot. Message me at walter.muntzenberger@sap.com.
Al Kalafian: We do have the SAP HANA/SAP Vora demo environment up and running in the Lenovo Executive Briefing Center. This demo was built by a team consisting of developers from SAP, Lenovo, SUSE, and MapR. If you would like to see a demo of its capabilities and explore the underlying architecture, contact me at akalafian@lenovo.com.
Walter Muntzenberger: I want to thank everyone for all the great questions. It certainly is a very exciting time with all these new technologies and the innovation that we can now do for our customers and that you can do for your businesses.
Matthew Shea: Thank you, everyone, for joining us today.





