Do you compress data packages loaded into BW InfoProviders? SAP says you should, but why? Learn why the periodic compression of BW InfoCube data is a good idea.
Key Concept
InfoProviders have two types of fact tables to hold key figure data. Although both are similar, the E fact table stores compressed data, while the F fact table stores uncompressed data.
SAP recommends that you compress data packages loaded into a BW InfoProvider as soon as possible. However, many people don’t know the reason for compression or what the compression job actually does. I will explain compression in detail and show why it is important to the overall health of your BW system.
Compression is an option under the Manage tab of every basic BW InfoCube. To see this option, right-click on an InfoProvider and choose Manage. The compression selections are found in the Collapse tab (Figure 1).

Figure 1
The Collapse tab shows the compression options for an InfoCube
What Does Compression Do?
The goal of compression is to reduce the amount of data that is stored in an InfoProvider. To understand how compression does this, I must first discuss the tables associated with the InfoProvider. Every InfoProvider has two fact tables that store data: the F fact table and the E fact table. To see the tables associated with an InfoProvider, use transaction RSRV (Figure 2). The F fact tables are automatically created and named /BI0/Exxxx and /BI0/Fxxxx, where xxxx corresponds to the InfoCube name.

Figure 2
Transaction RSRV, option for database information about an InfoProvider allows you to see all tables associated with an InfoCube. Note the two fact tables at the bottom.
Data that is loaded into an InfoProvider is first loaded into the F fact table. The system assigns a unique request identifier (Request ID in Figure 3) to each data package that has been loaded into the InfoProvider. This is set as part of the key of the data load package. The request identifier designates and separates the different data requests that have been loaded into the InfoProvider.

Figure 3
All requests loaded into the InfoCube are shown. Any package that has a check in the Compression column has been compressed. In this case, one package is compressed and the other is not.
Once a request has been compressed, the system flags the request as compressed in the Manage screen of the InfoPackage. Thus, an InfoCube can have multiple requests, some compressed, some not compressed. Compressed requests are stored in the E fact table; uncompressed requests are stored in the F fact table (Figure 3).
If an InfoProvider has not been compressed, the system keeps the request identifier as part of the key structure of data. This can cause tremendous inefficiencies when reporting because the same data can appear multiple times in the uncompressed InfoProvider.
For example, an order InfoProvider is created with the characteristics customer, material, calendar month/year, and order quantity. If data is loaded daily into the InfoProvider and one transaction record’s order quantity changes in the source system five times in five different days, the corresponding data that loads into the InfoProvider appears five separate times in the F fact table of an uncompressed InfoProvider.
Since the system keeps the request identifier in the data each time it is loaded, that same order has five different loads and five different request identifiers. As a result, the F fact table has five different records for that one order. A query that is created on this order data must aggregate the five requests at query runtime. This adds significant performance overhead to the query processing.
If this order InfoProvider is compressed, the system physically moves the data from the F fact table that is keyed by the request identifier to the E fact table that is not keyed by the request identifier. This compresses the data because the request identifier is eliminated and the five records noted above exist as one record in the compressed E fact table of the InfoProvider. The system combines and aggregates all records with the same master data keys. Typically, this results in a 20- to 30-percent reduction in data volume depending on the data.
End users see no evidence that compression has been performed other than improved query performance due to the reduction of data. Data is automatically kept consistent after compression.
Note
The compression job is forbidden if a selective deletion is running on the InfoCube. Compression is also not possible while an attribute/hierarchy change run is active.
Compression runs sequentially on each data package. Thus, if many data packages need to be compressed, the compression process could take a long time, as each request must be compressed in order.
How to Run Compression
Compression can either be performed manually on individual request or scheduled after data loading in process chains. To run compression manually, data packages loaded into the InfoCube can be compressed individually by request identifier or all at once. If a Request ID is compressed, as shown in Figure 1, it and all uncompressed data packages that have been loaded prior to that package are automatically compressed.
It is possible to have the system automatically compress data loads when they are loaded into an InfoCube. In the Manage screen of the InfoCube, choose Environment and click on Automatic Request Processing (Figures 4 and 5). Next set the flag Compress after Roll Up. The system automatically starts a job to compress a package after either the data load is complete or, if aggregates are active, after the roll-up (or filling) of the aggregates.

Figure 4
Automatic Request Processing allows the system to compress automatically after each data package is loaded into the InfoCube

Figure 5
Automatic Request Processing flags
This is a worthwhile option if data is being loaded into an InfoCube periodically from one source. It may not be as advantageous if multiple sources are loading into an InfoCube, because it is usually more efficient to compress all data packages at one time once all data loads are complete. This way, you don’t have a scenario in which you are compressing while data is being loaded. In this case, do not use Automatic Request Processing.
Another option is to schedule the compression after all data loads in a process chain (Figure 6). The compression job can be placed in the process chain to be run after all data loads are complete.

Figure 6
Compression job in process chains — the compression job is the last one in this process chain
Disadvantages of Compression
One distinct disadvantage to compression stops many people from compressing data. Once data packages have been compressed, there is no way to back out or remove individual compressed packages from the InfoProvider. For example, if I have loaded order data into an uncompressed InfoProvider, I can simply delete one InfoPackage if I find an issue with that data load.
Once an InfoProvider has been compressed, it is impossible to remove one individual request because the system has eliminated the request identifier from the key once the compression job has been run. Since the request identifier is gone, you cannot delete one request. The only way to remove the data from the InfoProvider is to selectively delete InfoCube data based on other keys. One more option is to load the PSA data back into the InfoCube as a reverse posting. It is an option on the scheduler, but can be very difficult, if not impossible, to do in some circumstances.
It is possible to have some data in an InfoProvider that is compressed and some data that is uncompressed. The system aggregates the compressed data in the E fact table with the uncompressed data in the F fact table automatically. To compensate for the inability to remove compressed packages, many customers keep a few data loads uncompressed. This gives them the flexibility to back out recent loads if needed while keeping the majority of the data in the InfoProvider compressed.
Zero Elimination
Zero elimination is another performance-enhancing function that the system can perform during compression. Depending on the data model and source system data, records can be loaded into an InfoProvider with zero values in all key figures. This is inefficient because these records provide no reporting value and slow the overall reporting performance.
To eliminate these records, choose the With Zero Elimination option during compression (Figure 7). Selecting this option tells the system to remove any records with all key figure values equal to zero during compression. This reduces the data volume and thus provides better query performance. You should set the zero elimination flag whenever you run compression to ensure the zero records are eliminated from the InfoProvider.

Figure 7
With Zero Elimination flag shown on the Collapse tab in the InfoCube Manage screen
Aggregate Compression
Aggregates are mini-InfoCubes that contain subsets of data from a parent InfoProvider; they are created to improve query performance. If aggregates have been created from an InfoProvider, the system automatically compresses the aggregate data by default. In other words, data is loaded into an aggregate F fact table. The system then automatically removes the request identifier from the data and moves the aggregate data from the aggregate F fact table to the aggregate E fact table. This compresses the aggregate data and ensures that the smallest amount of data is stored in the aggregate.
A disadvantage of this approach is that it can cause some problems in BW if data load requests need to be deleted from an InfoCube. The compression of the aggregate takes out the request identifier and does not allow for one request to be removed from the InfoProvider without first deactivating and removing all data from the aggregate. To remove the request, you must first deactivate the aggregates and rebuild them after the package is deleted. This can take a long time if the InfoProviders are very large.
SAP provided an option in BW 3.0B and later releases to allow aggregates to be uncompressed. This setting allows for the request identifier to remain as part of the aggregate, thus allowing packages to be removed from the aggregate. The packages can be deleted from the aggregate because the system keeps the request identifier of the data load in the aggregate and can find individual data loads by this request identifier (Figure 8).

Figure 8
Aggregates compression flag shown on the Rollup tab in the InfoCube Manage screen
A disadvantage of setting the aggregates to uncompressed is that it increases the volume of the aggregate, thus decreasing performance because data cannot be summarized across data packages. I recommend that you compress aggregates unless you need to back out data from the aggregates on a periodic basis.
Partitioning
Partitioning is a performance-enhancing technique that separates the InfoProvider into multiple transparent database tables to enable parallelization and provide better query performance. This occurs because the multiple partitions each contain portions of data and queries across these partitions can gather data in parallel, thus improving performance. Partitioning can be set in the InfoProvider on the calendar month or the fiscal period. This is set in the InfoProvider options shown in Figures 9 and 10.

Figure 9
Partitioning of an InfoCube — choose Extras and the Partitioning option
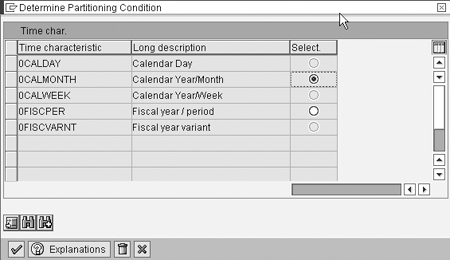
Figure 10
Partitioning can be set by either 0CALMONTH or 0FISCPER
Many people are not aware that only the E fact table is partitioned when the partitioning option is set. Thus, if data has not been compressed and moved from the F fact table into the E fact table, the data is not partitioned at all. Simply put, if compression is not run, there is no partitioning of data in the InfoProvider, even if the partitioning option is set.
To achieve optimal reporting performance and enable parallel processing of queries across partitions, InfoCubes should be compressed. This ensures that the system is partitioning the data in the InfoCube.
Non-Cumulative Key Figure Compression
Another feature of compression is to consolidate and recalculate the reference point of non-cumulative key figure values. Non-cumulative key figures are special key figures that cannot be summed. For example, I could track the key figure representing the number of employees in a company. If the number of employees loaded into the InfoProvider is 200, and this number changes to 220 and is also loaded into the InfoProvider, the records cannot be summed. I do not have 440 employees, I have 220 employees. This key figure cannot be aggregated; thus, this key figure is set as a non-cumulative key figure.
When keeping track of non-cumulative key figures, the system must store a reference point in the E fact table and track the additions or subtractions from this reference point. Each time data is loaded into a non-cumulative key figure, the system stores both the reference point and the outflow or inflow from this reference point.
In the example shown in Figure 11, five loads of values have been loaded into the non-cumulative key figure value. If uncompressed, the system must add the inflows and subtract the outflows of values from the reference point at the time of query run-time when a query is run on this key figure. The values for January, February, and March, therefore, are uncompressed. The system must add the material flow and the reference point to get the value for this key figure. Once compression occurs in April, the system combines the records and establishes a reference point based on the compressed data, thus reducing the data volume. If many uncompressed requests exist in the InfoProvider, this can be costly for performance.
|
|
|
F fact table
|
E fact table
|
| Jan-05 |
ABC1
|
1000
|
10
|
10
|
| Feb-05 |
ABC1
|
1000
|
20
|
10
|
| Mar-05 |
ABC1
|
1000
|
5
|
10
|
| Compression |
|
|
|
|
| Apr-05 |
ABC1
|
1000
|
3
|
45
|
|
| Figure 11 |
Reference points and material flow in the E and F fact table of an InfoCube |
To achieve the optimal query performance, compress InfoProviders as quickly and as often as possible. This is especially important for InfoProviders with non-cumulative key figure values or for InfoProviders that store volatile data on the source system. Compression can greatly improve query performance by reducing the amount of data that is accessed at query runtime.





