ou probably don’t need to use all the data in your APO source system for your BW-generated demand planning reports. Filtering that data so your query uses only what’s relevant will boost performance. Learn about three methods for carrying out this filtering: filtering in the source system, using the InfoPackage selection criteria, and filtering in update or transfer rules.
Companies that have been using BW or R/3 for a long time typically
have large volumes of data in their APO source systems. A portion
of this data is often not relevant for APO Demand Planning, as planning
is not necessary for all customers or materials. In many cases,
a small subset of the larger source dataset is actually loaded to
APO.
To keep APO populated with the proper data needed for planning,
filters need to be applied to the data. The simple selection criteria
available via the InfoPackage Select data tab (Figure 1)
is sometimes not enough to properly segregate the data. Instead,
you need complex filters to segregate data when loading from R/3
to APO, BW to APO, or even to InfoCubes within APO.

Figure 1
Selection criteria in the InfoPackage Select data tab
Dynamic filtering can make it much easier to provide only relevant
data in APO InfoCubes. This allows for better performance and future
growth. You have three options for applying these complex filters:
- Filter records in the source system. This technique takes advantage
of an ABAP user exit to filter in the BW or R/3 source system,
thus reducing the data at the point of extraction prior to loading
to APO.
- APO InfoPackage selection criteria. This allows specific fields
to be used for filters in the InfoPackage, either with simple
selection criteria or using ABAP routines for more complex selection.
- Filter in update rules or transfer rules. Filters are applied
during the loading process into APO InfoCubes.
I'll describe how and when you might use each method.
Filter Records in the Source System
Filtering applied at the DataSource provides a performance advantage
because network traffic bottlenecks are reduced when using a smaller
extracted dataset. For example, you may want to look at the 300,000
invoice records of one Company A division rather than the total
40 million invoice records in R/3. You could use selection criteria
in an APO InfoPackage, but this brings the full 40 million records
into APO. By using ABAP code with an SAP-supplied user exit, you
can eliminate the unneeded records in R/3 before loading them to
APO.
Use transaction CMOD in your R/3 system to implement
the user exit (Figure 2). Create a user-defined
project. Assign enhancement component RSAP0001
to the project. RSAP0001 can be used to enhance
or modify data used in the extraction engine. The user exit function
EXIT_SAPLRSAP_001 is called from within
RSAP0001
whenever a transactional DataSource extracts data. (See transaction
SMOD for details on this component, function, and
sample ABAP code.) All code is added to the user exit program included
in the component function. Add the ABAP user exit code shown in
Figure 3 to program ZXRSAU01 and
activate the project (Figure 4). Note that this
code is on the R/3 system, not APO.

Figure 2
Use transaction CMOD to create a user-defined project
data L_S_MC11VA0ITM like MC11VA0ITM,
L_tabix like sy-tabix.
case i_datasource.
when '2LIS_11_VAITM'.
loop at c_t_data into L_S_MC11VA0ITM.
l_tabix = sy-tabix.
if L_S_MC11VA0ITM-SPART ne '10'.
Else.
delete c_t_data index l_tabix.
continue.
endif.
modify c_t_data from L_S_MC11VA0ITM index l_tabix.
endloop.
Endcase.
|
|
| Figure 3 |
Program ZXRSAU01, the
user exit to filter records in R/3 |

Figure 4
Activate the project
This ABAP user exit code in ZXRSAU01 removes values from the internal
table c_t_data when they are not coded division 10(SPART
= ‘10'). It then loops through the internal table
c_t_data, which houses all extracted data during the extraction
process, looking at each of the records that are due for extraction.
Any record removed from c_t_data is no longer in the extraction
data package and is not brought over to APO. If a record does not
meet the division criteria, it is deleted from c_t_data.
The continue statement moves the system to the next record after
deletion. It is important to keep the indexes updated properly using
sy-tabix. This technique works with both full and delta
loads.
There is a downside to this filtering method. Since records that
are sent to APO are already filtered, you have no easy way to determine
the specific filter criteria applied to each data load. Thus, the
APO monitor does not show the selection criteria. To determine the
specific filters, you must analyze the user exit ABAP code. This
makes ongoing support difficult if the criteria are volatile, because
you must revisit the ABAP code for every change in criteria.
Note
To troubleshoot the user exit code, use a breakpoint in
ZXRSAU01
and test the transactional load using transaction RSA3
(Figure 5) on the R/3 system. The system starts a test
extraction and stops the extraction at the breakpoint, allowing
you to single-step through the process to see which records
are being filtered. RSA3 can also be run for
selected records using selection criteria to see how specific
records are filtered.

Figure 5
Test the transaction load with transaction RSA3
This user exit, ZXRSAU01, is also valid when exporting
data from BW to APO using export DataSources. To implement the user
exit, follow the steps outlined above and substitute a BW export
DataSource in place of the R/3 DataSource. This technique can also
be used for filtering master data or text. In both cases, use
EXIT_SAPLRSAP_002
and program ZXRSAU02. The coding technique is similar.
APO InfoPackage Selection Criteria
The typical filtering technique when loading data into APO is
to populate the values needed inside the InfoPackage via its selection
criteria. Sometimes a more dynamic approach is needed to determine
the filter criteria, especially if the filters differ each time
the data load takes place or the selection criteria is too complex.
Custom ABAP routines in InfoPackages allow for a more dynamic selection.
Say, for example, a company has 12 divisions. New divisions are
often being added to R/3. Data loaded into three InfoCubes is currently
segregated into groups of four divisions for the purpose of data
segregation and performance. The result is three InfoCubes, each
housing the data of four divisions. If dynamic selection is not
used, the four divisions are specified in each of the three InfoPackages.
An issue occurs when new divisions are added to the R/3 system.
Because of a lack of awareness of changes on the R/3 side, you might
not know about new data until after transactional data has already
been created. You then lose this transactional data until a reload
can occur and, in this case, add the new division to existing InfoPackages
and InfoCubes. If you could dynamically determine all new divisions
entered into master data, you could then pick up the new division
immediately in one of the InfoPackages and add it to the InfoCube.
All three InfoCubes need to be loaded with transactional data
relevant to divisions. The first two should use selection criteria
in the InfoPackages and specify the divisions. The third should
receive data from all other divisions not included in the first
two InfoCubes. To determine the divisions for which you need to
create code, read the division master data table and exclude those
divisions that are not selected in the other InfoPackages. This
assumes that any new division is entered into master data and the
master data division table is being loaded to APO periodically.
If a new division is added to R/3, it would be automatically added
to the APO division master data table, and, in turn, to the third
InfoCube selection criteria. Because master data is always loaded
before transactional data, even if a new division is added and immediately
populated in the transactional data, the new filter values pick
up the new division.
To use the selection criteria in an InfoPackage, enter 6 in the
data- selection Type field (Figure 6).
This allows for a custom routine to be created. The selection
criteria allows for single values, exclusive single values, ranges,
and exclusive ranges. The code adds range values to the InfoPackage
selection (Figure 7). You can fill the following
fields in the selection code:

Figure 6
Enter the value 6 in the Type field
data: l_idx like sy-tabix.
tables: /BI0/TDIVISION.
read table l_t_range with key
fieldname = 'DIVISION'.
l_idx = sy-tabix.
select * from /BIO/TDIVISION where DIVISION ne '01' and
DIVISION ne '10' and
DIVISION ne '20' and
DIVISION ne '30' and
DIVISION ne '40' and
DIVISION ne '50'.
l_t_range-sign = 'I'.
l_t_range-option = 'EQ'.
l_t_range-low = /BIO/TDIVISION-DIVISION.
l_idx = sy-tabix.
append l_t_range.
|
|
| Figure 7 |
InfoPackage selection code |
l_t_range-sign - Use I if the value is inclusive
or E if it is exclusive.
l_t_range-option - Use EQ (equal) if single values
are specified, BT (between) if the range is inclusive,
or NB (not between) if the range is exclusive.
l_t_range-low - Populate this with the lower interval
limit if a range is used. Fill this value if single values are used.
l_t_range-high - Populate this with the higher
interval limit if a range is used. Leave blank if single values
are used.
l_idx - Populate this index with the system table
ID sy-tabix.
Note
InfoPackage selection routines are stored only in the InfoPackage.
This makes them vulnerable if a user deletes the InfoPackage.
Make a backup of this code to prevent its loss in the case of
InfoPackage deletion.
Filter in Update or Transfer Rules
Complex criteria can be added to filter data via transfer rules
or loading to an InfoCube via update rules. For example, a custom
attribute APO relevant could be created and added
to the master data table for 0MATERIAL. This designates
master data records that are planned in APO. You want only those
records to be loaded from ODS to an InfoCube.
Records exist in the source system that have both Y and
N APO relevant flags. Thus, the master
data attributes of each record are examined to determine its relevancy
for the InfoCube.
Tip!
Update rules also allow the use of RETURNCODE in characteristic
routines to skip records. It is often better for performance
to use a start routine, as it allows all filters to be in one
place.
Figure 8DATA_PACKAGEDATA_PACKAGE/bio/pmaterial/bic/z_aporelDATA_PACKAGETip!
To troubleshoot the start routine, add a breakpoint to it and
simulate the data load from the PSA. To do this, right-click
on the data package in the PSA and choose Simulate/Cancel
Update (Figures 9 and 10).
data: i_out_package like DATA_PACKAGE,
l_tabix like sy-tabix.
Tables: /BI0/PMATERIAL
loop at DATA_PACKAGE.
l_tabix = sy-tabix.
Select single /bic/z_aporel into /bio/pmaterial-/bic/z_aporel from
/bio/pmaterial where material = DATA_PACKAGE-MATERIAL and
OBJVER = 'A'.
If /bio/pmaterial-/bic/z_aporel = 'Y'.
else.
delete DATA_PACKAGE index l_tabix.
continue.
endif.
modify DATA_PACKAGE.
endloop.
ABORT = 0.
|
|
| Figure 8 |
The start routine to filter records
in an update rule |
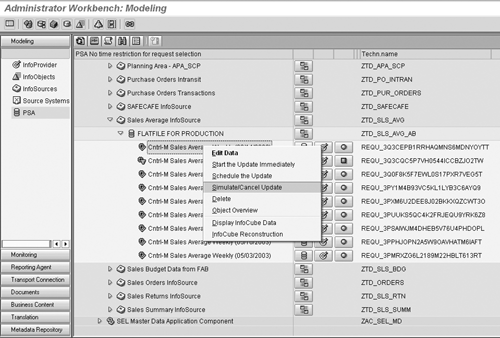
Figure 9
Select the data package in the PSA and then select Simulate/Cancel Update
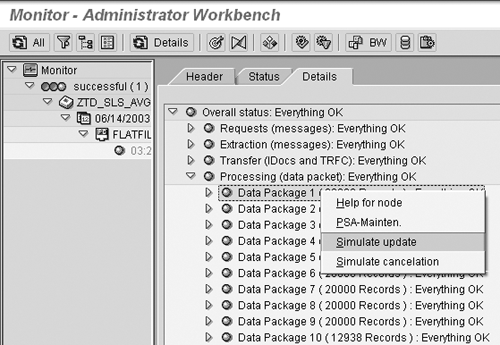
Figure 10
Select Simulate/Update to begin simulating the data load
It is important that all filters be adequately tested before being
implemented into a production environment. Any ABAP code should
be examined to make sure it is as efficient as possible. However,
these techniques should allow you to have a more flexible and capable
APO data model.



