Near real-time data is not possible as standard with InfoCubes in SAP NetWeaver BI 7.0. Only DataStore objects can use real-time data acquisition (RDA). However, InfoCubes provide better performance than DataStore objects. Find out how you can model InfoCubes to facilitate near real-time data.
Key Concept
Real-time data acquisition (RDA) is a new capability that you can use with DataStore objects in SAP NetWeaver BI. It allows you to load data from an SAP or Web service source system on a minute-by-minute basis. With clever modeling you can simulate this capability with InfoCubes and keep your data just as up-to-date.
Think back to when you first started deploying a data warehouse. One of the first things you explained to your users is that their reports/outputs would not be up-to-date. Rather, they would show only the data that had been loaded into the data warehouse over the weekend or as of last night. Can you remember their response? Most people were probably shocked at this limitation. After all, the whole point of their ERP environments is that data would be up-to-date and they would avoid batch processing.
Several years later, data warehouses have become common, and users have grown accustomed to data having a latency of at least one day. But now, real-time data acquisition (RDA) in SAP NetWeaver BI is becoming a reality, so users can eliminate data latency. I will show you why this is useful.
Two scenarios instantly spring to mind. First, up-to-date analytics information can be vital to operational decision-making. Consider customers who are approaching their credit limit. Credit checking might normally be performed in the ERP system. However, some organizations might have more than one ERP environment (e.g., for different geographies), so they want a consolidated credit check across all systems.
Alternatively, the organization might check credit at a consolidated group level (that is, combining different legal entities). The customer could place two orders in the same day that do not individually exceed their credit limit but do so when combined. As the data warehouse has only the data from the last day, these orders are allowed to go through. With near real-time data, the second order would be blocked because the first order would have been factored into the credit limit. The company could save a significant amount of money in the event of non-payment.
A second scenario involves the organization that operates around the clock. This might be a global organization with a single data warehouse or a business that, by its nature, is 24x7. For these companies, it is unacceptable to have a data warehouse performing a large batch load overnight, especially if this disrupts reports. There are no off-peak hours, and everyone expects the latest information all the time.
For companies like this, SAP NetWeaver BI provides RDA, which allows DataStore objects (DSOs) to have up-to-the-minute information. Users no longer need to deal with the traditional limitations of data warehousing.
The Performance Issue
DSOs are the only data targets that you can use for RDA, but they are not suitable for outputs requiring high performance. DSOs are useful for operational, detailed reporting on a small subset of data. Performance issues arise because DSOs are not well suited to multi-dimensional analysis.
The best InfoProvider for high-performance analysis is the InfoCube (which can perform ever better with SAP NetWeaver BI Accelerator). Unfortunately, in the current release of SAP NetWeaver BI, RDA is restricted to DSOs, and SAP NetWeaver BI Accelerator is restricted to InfoCubes. Therefore, it is not possible to use RDA with InfoCubes (and thus, SAP NetWeaver BI Accelerator). This prevents you from delivering the kind of high performance that users can now expect from SAP NetWeaver BI when dealing with near real-time data.
However, help is at hand. You can combine a DSO for RDA and an InfoCube by a union operation using a MultiProvider. If you store the majority of the data in the InfoCube and only the latest data in the DSO, you can deliver high performance while still keeping the data up-to-date. This technique effectively allows near real-time data for InfoCubes (for improved performance), which is not normally possible. This article shows you how to achieve this goal.
A Simple Start
The obvious starting point is one DSO, one InfoCube, and one MultiProvider. I assume you are familiar with creating all these objects, as much has been written on the topic. In addition, I assume that you understand how to set up a DSO for RDA, as I will be looking at what happens after this point.
In the starting model, you create transformations to move data from the DSO to the InfoCube (Figure 1). You include both the DSO and the InfoCube in the MultiProvider. For simplicity, I assume the DSO, InfoCube, and MultiProvider all have the same InfoObjects. I will develop the model further during the course of this article.
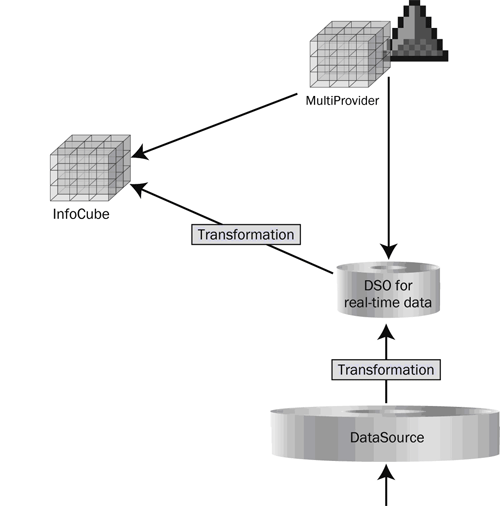
Figure 1
Initial (simple) model
The objective with this model is to keep as much of the data in the InfoCube (which can then leverage SAP NetWeaver BI Accelerator) as possible. To do this, you need to move data regularly from the DSO into the InfoCube. However, as the MultiProvider combines the data in the DSO and the InfoCube by a union operation, you need to be careful to avoid double-counting.
Note
RDA uses the concept of an open request (similar to integrated planning). The system or the developer needs to set the request to “closed” before the data within it can be loaded into other data targets. Two process types are available for process chains to manage this task. The first closes an open request, while the second starts and opens a new request.
Table 1 shows the sequence of steps necessary to move the data from the DSO into the InfoCube. I have used letters to show data sets (these could be any number of records from any number of requests) as they move between or are deleted from InfoProviders. For example, if the InfoProvider holds sales orders, the letter “A” might represent all the sales order records loaded in all the requests up to that point. You can set up all the steps in a process chain so it is fully automated. You can decide how frequently the process chain should run. However, SAP advises that it be no more than once per hour, or the number of requests will become unmanageable.
| Start |
|
|
|
| Near real-time data acquired |
A |
|
A |
| Close RDA request |
A |
|
A |
| Load all data from DSO to InfoCube |
A |
A |
2 x A |
| Delete all data in DSO |
|
A |
A |
| Restart RDA |
B |
A |
A, B |
|
| Table 1 |
Initial (simple) model steps |
Note
You could include an additional step in Table 1 after every InfoCube load (for all models) that builds SAP NetWeaver BI Accelerator indexes and database statistics, for example. I have not included it here as it is an optional step that can take place in your process chain.
The second problem occurs while loading the data from the DSO into the InfoCube. When the load completes, the MultiProvider double-counts the data because it exists in both the DSO and the InfoCube. Therefore, for a short period, the data is inaccurate.
For most situations, the inaccuracy is present for only a short period. This is because the data is not included in reports until the load into the InfoCube has completed and the complete status has been set to OK. As the deletion of data in the DSO is a full deletion, this is a very quick process.
Note
An option in BEx Queries is to use the Most Recent Data option. This option includes data in the BEx Query from InfoProvider requests even when the complete status of the request in the InfoProvider is not OK (i.e., the request has a yellow traffic light).
Most Recent Data Most Recent Data Continuous RDA
Consider how to overcome the first problem: pausing the RDA. Ensure that all the data in the DSO is moved into the InfoCube because you need to delete the old data in the DSO to prevent double-counting in the MultiProvider. If you restart the RDA request to gather new data before deleting the old data in the DSO, you are prevented from deleting the old data. Newer requests exist in the DSO, so the system prevents the deletion of the older individual requests. You do not want to delete all the data because the new data from the restarted RDA request would not exist in the InfoCube (because it has not been loaded into the InfoCube).
You can solve this problem by using a second, duplicate DSO. This allows you to load the second DSO while the first is still moving its data. Figure 2 shows the model for this procedure.
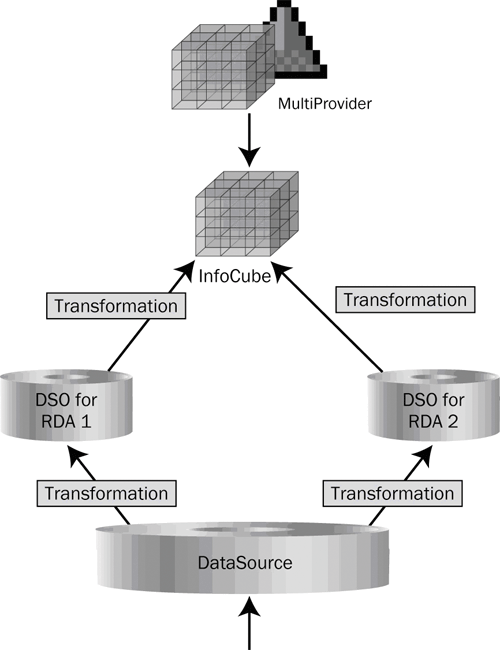
Figure 2
Continuous RDA model
The model works by toggling between the DSOs, which allows data to load continuously while one DSO is occupied with pushing data into the InfoCube. The mechanism is still quite straightforward and can be achieved using normal process chain variants. Table 2 shows the full flow of data sets moving between objects as each step is performed.
| Start |
|
|
|
|
| Near real-time data acquired |
A |
|
|
A |
| Close RDA request for DSO 1 |
A |
|
|
A |
| Open RDA request for DSO 2 |
A |
B |
|
A,B |
| Load all data from DSO 1 to InfoCube |
A |
B |
A |
2 x A, B |
| Load all data from DSO 1 to InfoCube |
|
B |
A |
A,B |
| Close RDA request for DSO 2 |
|
B |
A |
A,B |
| Open RDA request for DSO 1 |
C |
B |
A |
A, B, C |
| Load all data from DSO 2 to InfoCube |
C |
B |
A,B |
A,2 x B, C |
| Delete all data in DSO 2 |
C |
|
A,B |
A, B, C |
|
| Table 2 |
Continuous RDA model steps |
The RDA request is reopened as soon as it is closed. There is no delay in processing the new data, so the information stays up-to-date because both DSOs are within the MultiProvider. However, notice that the second problem remains. While the data is being loaded into the InfoCube, duplication occurs. The difficulties described in the first model are still present. Therefore, the model needs further refinement.
Single-Counting
So, how do you eliminate the issue of double-counting? You need to create a model in which the MultiProvider doesn't start using the data in the InfoCube until after it has been deleted from the DSO. Unfortunately, there is no simple way of achieving this goal using standard configuration. However, you can minimize the amount of custom activity by introducing a second InfoCube, as shown in Figure 3.
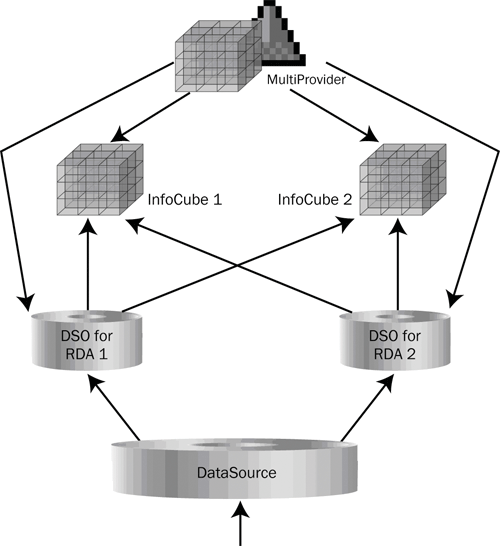
Figure 3
Single-counting model
This model looks complicated, but it is quite straightforward. The InfoCubes and DSOs are identical and all four data targets are used within the MultiProvider. Both DSOs can load data into both InfoCubes.
The secret with this model is using only three of the data targets at any one time. The MultiProvider ignores at least one data target — the one in which you load data. Later, I will show you how to make the MultiProvider use only a subset of the data targets. For now, assume this is possible and examine the sequence of activities in Table 3. To assist you, I have highlighted which data targets are used by the MultiProvider at any one step.
| Start |
|
|
|
|
|
| Near real-time data acquired |
A |
|
|
|
A |
| Set MultiProvider to use DSO 1, DSO 2 and InfoCube 2 |
A |
|
|
|
A |
| Close RDA request for DSO 1 |
A |
|
|
|
A |
| Open RDA request for DSO 2 |
A |
B |
|
|
A, B |
| Load all data from DSO 1 to InfoCube 1 |
A |
B |
A |
|
A, B |
| Set MultiProvider to use DSO 2 and InfoCube 1 |
A |
B |
A |
|
A, B |
| Load all data from DSO 1 to InfoCube 2 |
A |
B |
A |
A |
A, B |
| Delete all data in DSO 1 |
|
B |
A |
A |
A, B |
| Set MultiProvider to use DSO 1, DSO 2 and InfoCube 1 |
|
B |
A |
A |
A, B |
| Close RDA request for DSO 2 |
|
B |
A |
A |
A, B |
| Open RDA request for DSO 1 |
C |
B |
A |
A |
A, B, C |
| Load all data from DSO 2 to InfoCube 2 |
C |
B |
A |
A, B |
A, B, C |
| Set MultiProvider to use DSO 1 and InfoCube 2 |
C |
B |
A |
A, B |
A, B, C |
| Load all data from DSO 2 to InfoCube 1 |
C |
B |
A, B |
A, B |
A, B, C |
| Delete all data in DSO 2 |
C |
|
A, B |
A, B |
A, B, C |
|
| Table 3 |
Single-counting model steps |
This sequence avoids double-counting at any point, while continually loading data in near real-time. This goal is achieved by using two identical InfoCubes to duplicate the information and requires more database capacity. Nonetheless, for mission-critical analytics that require up-to-the-minute data and high-performance analysis, this is the most appropriate option.
So how do you dynamically change the MultiProvider to use different data targets? The secret is that you don't. Instead of changing the MultiProvider, you use a variable within your BEx queries. This variable uses the special characteristic 0INFOPROV, which is available to all BEx queries based upon a MultiProvider. By using this variable, you avoid double-counting data and inaccuracies in your MultiProvider.
Create your own variable for this characteristic (as you would for any other) and set it to be processed by the customer exit. Then ensure that this variable is used in every one of your BEx queries on this MultiProvider.
You need to write some ABAP code in the normal Business Add-In (BAdI) for variables. This code acts as a filter on the MultiProvider and returns values telling the BEx query which data targets to use. There are various ways to write the code, and your developers might have their own preferences. I have provided an example of the logic without mandating the exact coding. I recommend using two custom tables, as defined in Tables 4 and 5.
| MultiProvider |
Yes |
The technical ID of the MultiProvider that is being used for this purpose |
To identify the MultiProvider that needs to have its data targets filtered |
| Step |
Yes |
Sequential number for the step in the process |
To list the different steps the MultiProvider can have |
| InfoProvider |
Yes |
InfoProviders valid during this step |
To list all the InfoProviders that should be included within the current step |
|
| Table 4 |
MultiProvider configuration table |
| MultiProvider |
Yes |
The technical ID of the MultiProvider that is being used for this purpose |
To identify the MultiProvider that needs to have its data targets filtered |
| Step |
Yes |
Sequential number for the step in the process |
To list the different steps the MultiProvider can have |
| Active |
No |
Currently active step |
This is a flag used to determine the current step in the sequence. |
|
| Table 5 |
MultiProvider data table |
Table 4 should be used as a configuration table. This can list all the changes that are valid for the MultiProvider as it moves through its sequence. Table 6 shows an example that applies to the model. Table 5 can then be used to flag the current step in the sequence, as in the example in Table 7 for step 3.
| MultiProvider |
001 |
DSO 1 |
| MultiProvider |
001 |
DSO 2 |
| MultiProvider |
001 |
InfoCube 2 |
| MultiProvider |
002 |
DSO 2 |
| MultiProvider |
002 |
InfoCube 1 |
| MultiProvider |
003 |
DSO 1 |
| MultiProvider |
003 |
DSO 2 |
| MultiProvider |
003 |
InfoCube 1 |
| MultiProvider |
004 |
DSO 1 |
| MultiProvider |
004 |
InfoCube 2 |
|
| Table 6 |
Example configuration for Table 4
|
| MultiProvider |
001 |
|
| MultiProvider |
002 |
|
| MultiProvider |
003 |
X |
| MultiProvider |
004 |
|
|
| Table 7 |
Example data for Table 5 |
A program can be executed during the process chain to change the current step in Table 5. The program can either use a variant to specify the particular step or can move onto the next step automatically. I would recommend the former. That way, when a process chain is restarted mid-flow, the active step remains synchronized and does not require manual adjustment.
Now, when the ABAP code for the variable executes, it follows this pseudo logic:
- Find the MultiProvider the BEx query is running on
- Look in Table 5 for the currently active step
- Using the currently active step, look in Table 4 for the valid InfoProviders
- Return the filter values using the valid InfoProviders
This filters the BEx query to use only the InfoProviders you have deemed to be active for that particular step. With this step in place, your model is complete, and you will never double-count your data.
Duncan Foster
Duncan Foster is an information strategy consultant with CSC EMEA NR (Ireland, Netherlands, and UK) and is responsible for SAP NetWeaver's advancement. He specializes in helping organizations determine management information and performance management strategies, as well as supplies architectural oversight and project management services. He has worked with SAP since 1999 and SAP NetWeaver BI since 2001, improving the business performance and quality of decision making for thousands of users.
You may contact the author at dfoster20@csc.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.





 Premium
Premium