David Duncombe shows how to use an extended table introspector utility class to dynamically generate a formatted representation of internal tables at run time, with added support for output to a Microsoft Excel workbook. This offers a more natural way to format long text data.
Key Concept
The iXML library is an API that offers core Extensible Markup Language (XML) services. These services can be exploited to construct XML documents that represent information in a Microsoft Excel workbook.
I outline why this additional output format is so useful and then briefly compare some of the options available to export data to Microsoft Excel from an SAP NetWeaver environment. Next, I describe a demonstration program focusing on the new capabilities of the class. I also explain the implementation changes made to the class to accommodate the extended functionality.
Note
My first article, titled “
Dynamically Generate a Formatted
Representation of Internal Tables for Output,” examined the
implementation details of the original table introspector utility class.
Because this article mainly focuses on the necessary changes
made to the original implementation, a proper understanding of the
original implementation is important. In light of this, you are
encouraged to review my first article before proceeding if you have not
done so already.
You can view the code as follows:
Click here to see the source code for the long text upload program z_introspector_load_text
Click here to see the source code for the demonstration program z_introspector_excel_demo
Click here to see the source code for the table introspector utility class zcl_bc_table_introspector_source
Click here to see Extended Table Introspector Utility Readme
Exporting Data to Microsoft Excel
It is a common request in the business world to have output from the SAP system made available as a Microsoft Excel file. The reasons for such requests vary. Some users may simply feel more comfortable using a spreadsheet application. Other users may rely on the advanced formatting or processing features that are only possible with a spreadsheet application. For example, many users like to have the ability to sort the data, or to apply conditional formatting based on a formula of some kind.
In many instances, it is possible to satisfy these differing requirements by outputting data to a Comma Separated Values (CSV) file. The CSV file format is a commonly used format in which data is organized into an arbitrary number of records separated by line breaks. Each record is further divided into fields, usually separated by the comma character. Once the data is output into a CSV file, the file can be opened by the spreadsheet application and the user is able to process the data further using advanced features.
However, in some instances it is difficult or impossible to satisfy a requirement using a simple CSV file. One particularly common requirement which is difficult to satisfy using a CSV file is the output of long text data. Although it is possible to represent long text using the CSV file format, it is awkward to deal with such text when it spans multiple lines. In this case, it is desirable to present such data in a spreadsheet in order to take advantage of the fact that the cell concept allows such text to be stored sensibly.
The requirement for representing long text data acts as the main driver for extending the table introspector utility class. By adding an additional output type to represent the introspector state as a Microsoft Excel workbook, it becomes possible to represent long text easily. In addition to this, the new output type affords you the opportunity to use other features that you would only find in a spreadsheet format. These features are outlined in the relevant sections later in this article.
In the following sections I want to briefly review some of the options available to generate files that can exploit the processing and formatting capabilities of Microsoft Excel. An exhaustive treatment of the relevant options is beyond the scope of this article. Where the options are based on SAP-delivered technologies, more information can be found at https://help.sap.com.
Object Linking and Embedding Automation
Object Linking and Embedding (OLE) Automation is a technique developed by Microsoft to facilitate communication between processes. The mechanism provides for an automation server to export automation objects, which can then be manipulated by automation clients via properties and methods. In this way, desktop applications (including Microsoft Excel) can act as an automation server to expose their functions to third-party applications.
OLE Automation is supported in ABAP through a set of OLE-specific language elements. These include the commands CREATE OBJECT, CALL METHOD, GET PROPERTY, SET PROPERTY, and FREE OBJECT. Each command can be mapped to a special OLE function module residing in the SAPGUI which is called via a Remote Function Call (RFC). In this way, the SAPGUI represents the automation client and is able to mediate communication between the ABAP program and the automation server.
Note that because OLE Automation relies on connections being made from the program to the front end (where both the automation client and automation server reside), it is not possible to run the program from a background work process. This can be a serious drawback in many circumstances.
Desktop Office Integration
Desktop Office Integration (DOI) provides an object-oriented wrapper to the OLE Automation technique. At a high level, there are two special controls that mediate communication between the SAP system and the desktop application. The SAP Document Container Control resides in the SAPGUI, and communicates with the desktop application using the OLE interface. The SAP Data Provider is responsible for buffering SAP data, which can be inserted into documents using links.
Extensible Markup Language-Based Processing
Extensible Markup Language (XML) is a meta-language that is designed to model arbitrary document formats. The rules for encoding documents are found in the XML schema, which is responsible for formally defining the constraints on the structure and content of the documents. Although XML is perhaps best known as a data interchange format used for exchanging data over the Internet, it is also used in a number of different applications. In particular, it is used by many office suite packages to represent document file formats.
The Microsoft Office 2003 XML formats introduced a new way to represent documents in Microsoft Office. The public availability of the schemas presented an opportunity for developers to take advantage of the new XML-based format to produce documents on the fly. SpreadsheetML is the XML schema used by Microsoft Excel 2003.
Since the release of Microsoft Office 2007, the Office Open XML (OOXML) file format has been adopted. Unlike the earlier schemas that stored the XML formats as single monolithic XML files, OOXML stores the data and metadata as a multi-part archive. The OOXML standard increases robustness, efficiency, and security.
Compared with OLE Automation and DOI, XML-based processing has a number of advantages:
- Processing can be done using background work processes
- Processing performance is improved
- Email attachments are easily created
- Advanced formatting is possible
The following are some of the technologies available to generate XML suitable for use in Microsoft Excel.
iXML
The iXML library offers three core services:
- The XML parser uses an XML document as input and creates an in-memory representation of it after ensuring that it is syntactically correct. You can access the representation using either the Simple API for XML (SAX) or Document Object Model (DOM) processing models.
- The XML DOM implementation represents the structure and content of an XML document using a series of classes and interfaces. It provides a way for the programmer to manipulate elements, attributes, and text data.
- The XML renderer writes the in-memory representation of the XML document into a bytestream.
The iXML library is implemented in C++ and is running in the ABAP kernel. The iXML library is available from SAP Basis Release 4.6C. A wrapper has been defined for this library that is implemented as a series of ABAP Objects classes and interfaces, allowing the library to be called from directly within an ABAP program.
Extensible Stylesheet Language Transformations
The Extensible Stylesheet Language Transformations (XSLT) language transforms a source data object into a target data object. The data objects can be either an XML document or an ABAP data structure. To create the transformation, an XSLT program is first created as a repository object. Then, together with the source data object, this is used as input to the XSLT processor, which in turn generates the target data object. The call transformation statement is used to execute XSLT programs from the ABAP environment.
Simple Transformation
Simple Transformation (ST) is an SAP proprietary language designed to simplify data transformation between ABAP and XML. The approach used is conceptually similar to that used by XSLT; however, ST only transforms ABAP data objects into XML (and vice versa). ST programs are symmetrical: both serialization and deserialization instructions are encoded in the single program. The call transformation statement is generalized and can also be used to execute ST programs (as well as XSLT programs).
ABAP2XLSX
ABAP2XLSX is a community project that offers a simplified, object-oriented framework to create OOXML documents directly from ABAP. Unlike the previous technologies, which provide general XML processing capabilities, ABAP2XLSX focuses specifically on generating Microsoft Excel documents. Essentially, it provides a layer of abstraction that hides the details that are performed using lower-level libraries. This abstraction simplifies use of features that pertain to spreadsheets without concern for how the underlying XML looks. Advanced features are made available and include formulas, multiple sheets, conditional formatting, cell data format, and graphs.
The distribution package for ABAP2XLSX includes a set of demonstration programs. The code in this program shows how easy it is to create a new workbook, set its title, and then populate some cells.
This completes the review of some of the options that allow you to export data to the Excel format. You will see later that the extended table introspector utility class implementation generates a SpreadsheetML file by using the iXML library. The SpreadsheetML format retains many of the capabilities of the OOXML format, but offers the compromise of simplicity (only a single file is produced). With the iXML library, you can dynamically generate the required XML elements from information that is only known at run time.
Before I show you the implementation in detail, I first explain the demonstration program.
The Extended Table Introspector Demonstration Program
I have modified the simple demonstration program used in my previous article to show the extended capabilities of the new table introspector class. As before, the data used to populate the internal table at run time is the ubiquitous Flight Data Model that is often used in examples provided by SAP. However, as the model does not store the long text that is needed to demonstrate the extended capabilities of the class, it is necessary to augment the model slightly.
The basic idea is to store a summary description of each airline in the model. To do this, a custom text object and text ID need to be created, and the text lines themselves then have to be loaded. See the Extended Table Introspector Utility Readme file for instructions on how to set this up before you run the demonstration program.
In contrast to the previous version of the demonstration program, note that several options presented on the selection screen relate to new features offered by the SpreadsheetML format (Figure 1). The selection screen shows that options now exist to specify both the document author and sheet name. In addition, the freeze header option allows the user to request that the header row remain visible while the rest of the sheet scrolls.
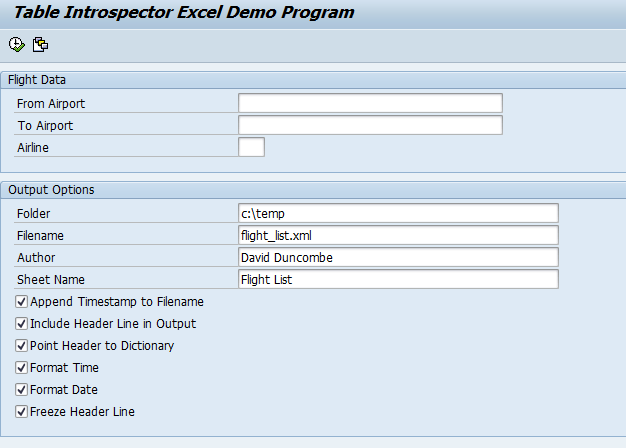
Figure 1
The demonstration program selection screen
The main method shown in Figure 2 is recognizable from the original demonstration program. However, even though the basic construction is similar, changes are required in three main areas. First, the flight details retrieved from the database need to be supplemented with long text describing each airline. Second, a different set of options now needs to be passed to the factory method so that the introspector object can be initialized to take advantage of the SpreadsheetML format. Third, the new getter method needs to be called to return the SpreadsheetML representation of the introspector state.

Figure 2
The demonstration program
These changes are outlined in more detail below. After the local class is instantiated, proceed with the following method calls.
1. The first method called is load_data, which as before calls the BAPI function bapi_flight_getlist to populate the internal table you need (Figure 3). In addition, flight list data returned from the BAPI function is supplemented with long text. A text key is built using the text object, text ID, language, and airline ID. This key is passed iteratively to the read_text method to return the text lines for each airline. The internal table is stored as an instance attribute in the local class.
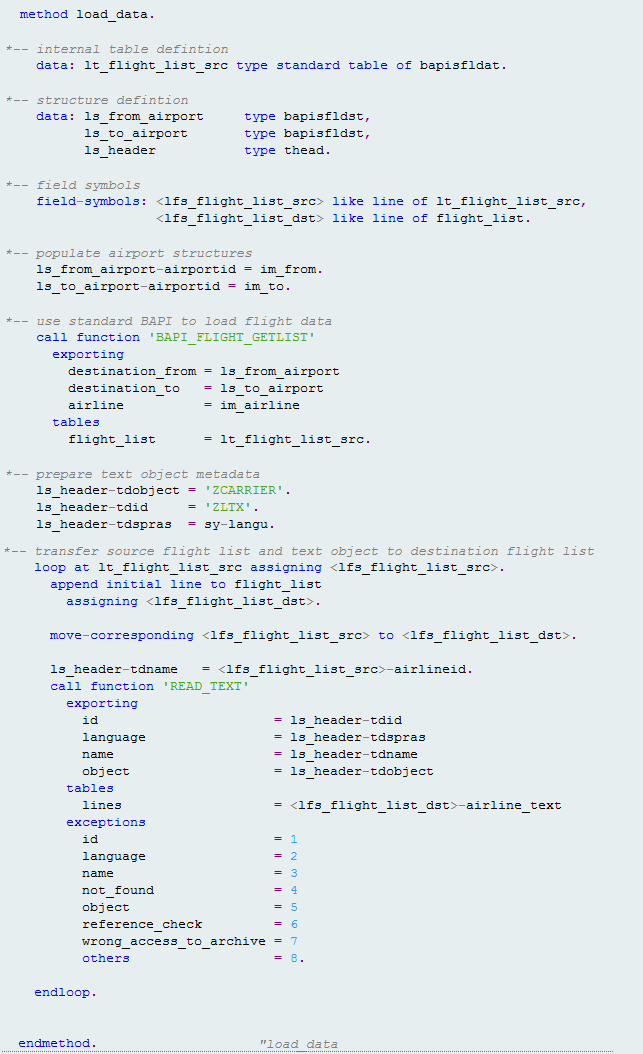
Figure 3
Populate the internal table with flight list data (including text lines)
2. The second method is responsible for initializing the table introspector using the appropriate factory method. In addition to the flight data that is passed to this method, user-specified formatting options are also provided. Several new options relate to formatting and are meaningful only when considering the SpreadsheetML format. Three such options have already been seen on the demonstration program selection screen in Figure 1: Author, Sheet Name, and Freeze Header Line. These options correspond to the factory method parameters im_author, im_sheet_name, and im_freeze_header respectively.
In addition, three more options exist that are lower level and more useful to the programmer. The im_header_color parameter sets the color of the header row according to an enumerated constant. The im_string_cell_width parameter sets the character width of the string cell. The im_points_factor parameter sets the average point size of a character.
After the factory method completes, a table introspector object is returned and stored as an instance attribute of the local class. In detail this looks like the code shown in Figure 4.

Figure 4
Call the table introspector utility class
3. The third method call is to the download method. At this point in program execution, the introspector has done the hard work and you only need to call the appropriate getter method. In this case, you want to download the file to disk using the SpreadsheetML format. Simply call the getter method get_xml_rendition. The table returned from this call is suitable to pass immediately to the standard method cl_gui_frontend_services=>gui_download (Figure 5).

Figure 5
Retrieving the internal table representation suitable for Excel output
4. To complete the demonstration program, a simple ABAP List Viewer (ALV) grid representing the data selected is again presented to the user. The display method of the local class does the necessary work by calling the appropriate getter method: get_alv_rendition. The object returned by this method is a reference of type cl_salv_table, and can be used in a standard fashion to export data to the screen (Figure 6).
Figure 6
Retrieving the internal table representation suitable for ALV output
Although the display method implementation is identical to that found in the original demonstration program, it does not display long text data in the screen output as you might expect. The reason relates to a limitation found in the ALV grid technology itself. As explained in SAP Note 857823, when data tables are sent to the front end, only character values of length 128 are allowed. This means that there is no natural way to present text that, by its nature, may exceed this length in an ALV grid.
There are workarounds you can use to represent long text data when the ALV grid is used. One is to represent each line of text in a separate cell in the grid, and then allocate sufficient cells to allow the complete text to be output. This is clearly awkward, but perhaps acceptable if no other option exists. Another is to register an event handler to react to a mouse button click on the relevant cell. The handler would then be responsible for opening a dialog to display the long text using the Control Framework. However, this approach presents difficulties if the long text is to be included in any printout of the grid.
The drawbacks of these workarounds for ALV grid output provide additional motivation to seek a more appropriate representation of table data when long text is involved. The SpreadsheetML format overcomes such drawbacks and offers an additional way to represent the data. The file downloaded to disk, when open in Microsoft Excel, looks like Figure 7.
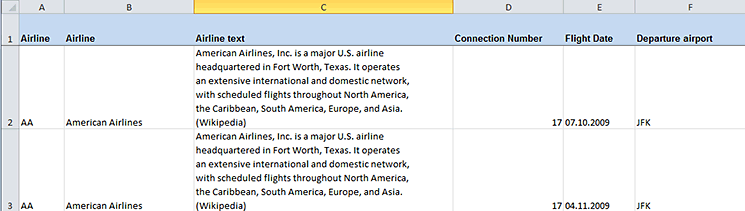
Figure 7
The internal table as Excel output
The output to the screen on completion of the transaction looks like Figure 8.
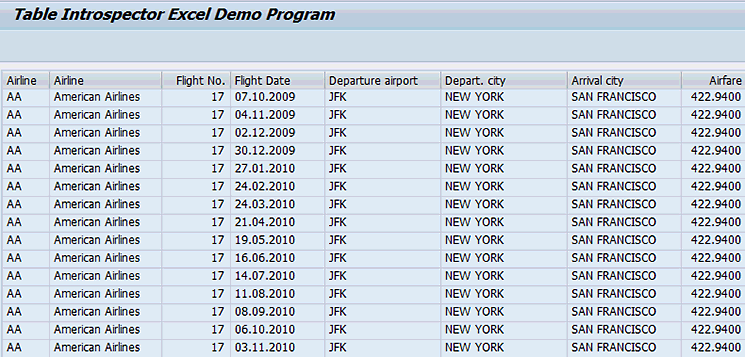
Figure 8
The internal table as ALV output
As you have now seen, minimal changes are required to the demonstration program to take advantage of the extended capabilities of the utility class. From a client programmer’s perspective, long text can now be easily handled without any subsequent manipulation of the text lines table format commonly used by the SAPscript programming interface. In addition, options related to the SpreadsheetML format are passed through to the factory method you already know. The new getter method call completes the set of changes.
Next, I examine the extended implementation details.
Extended Table Introspector Utility Class Implementation Details
Recall that the table introspector utility class is privately instantiated through one of two factory methods: factory_using_table or factory_using_sql. Although both factory methods have been modified to generate the SpreadsheetML representation of the introspector state, additional work related to processing text lines can only be meaningfully performed in the factory_using_table method. The reason it only makes sense to process text lines in this method is because the lines themselves must be represented in a nested internal table, and this type of object can only be passed to the factory_using_table method.
It follows then that in the current discussion, I focus on the method factory_using_table. The signature of this method can be seen in Figure 9.
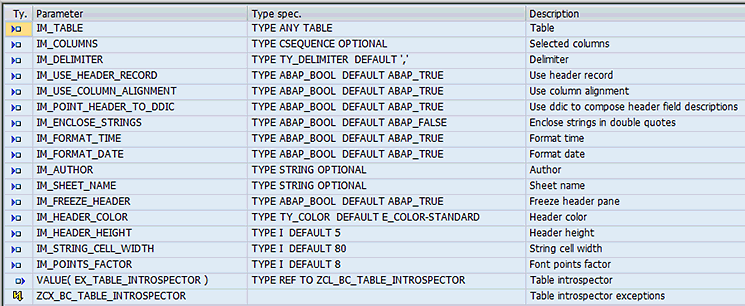
Figure 9
Signature of the internal table factory method
As before, an arbitrary internal table, together with formatting options, is accepted as input. Several parameters relate to the formatting of an XML spreadsheet. You should already be familiar with most of these parameters from the demonstration program walkthrough. Note that some parameters do not make sense in the context of an XML spreadsheet rendition, in which case they are ignored. For example, the parameter im_delimiter does not make sense for a spreadsheet rendition in which cells are represented using XML elements.
The return of the introspector object upon method completion, as well as the use of class-based exception handling, remains unchanged.
There are three changes to the factory_using_table method implementation that you need to know. I now describe each of these changes.
1. First, the call to method get_internal_table_metadata previously returned a flat collection of table components, filtered according to any supplied columns. In the extended implementation, a second component collection is returned to represent text lines. The call is shown in Figure 10.

Figure 10
Call to get table components with support for text lines
To be able to return the second component collection, the method implementation for get_internal_table_metadata must correctly handle elements that hold text lines. Inside this method, the call is made as before to recursive_filter_columns to resolve the table to a collection of elements. Previously, any elements that were found to be table types would have been ignored in the code. Now during processing, any elements found to be table types are tested for type compatibility against the text lines table. Figure 11 shows how components that pass this test are added to the returned component collection.
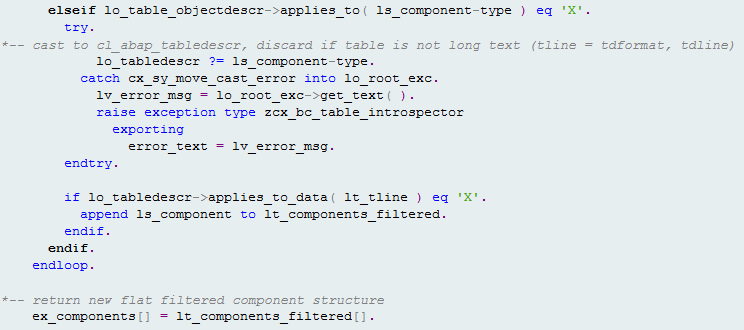
Figure 11
Processing elements that hold text lines
When the method recursive_filter_columns has completed and control is passed back to the method get_internal_table_metadata, the resolved collection is finally split into two separate collections. Only standard elements are included in the first collection, whereas standard elements as well as text line elements are included in the second collection (Figure 12).
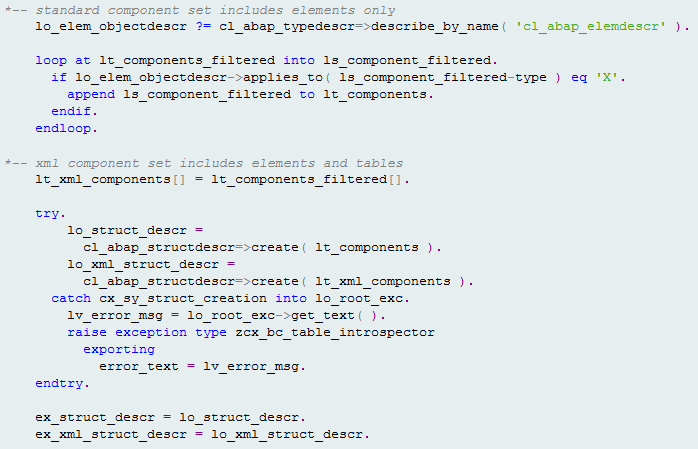
Figure 12
Resolving the components into two separate collections
2. Second, an additional method called populate_xml_table is introduced to process the new collection. This method is responsible for populating the new internal table (including text lines). The call is shown in Figure 13.

Figure 13
Call to populate the XML table
Similar to its sister method, populate_table, the populate_xml_table method works by creating source and target structures to copy data from the source internal table to the target (column filtered) internal table. Figure 14 shows the source structure at run time. The airline_text field contains the summary description of the airline as a nested table.
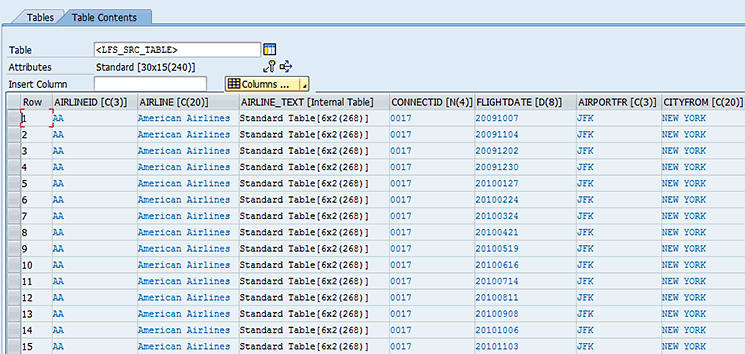
Figure 14
A populated source internal table showing a nested table
In contrast to its sister method, however, the populate_xml_table method must perform a simple conversion of the text lines to a string. The text lines look like what is shown in Figure 15 at run time.
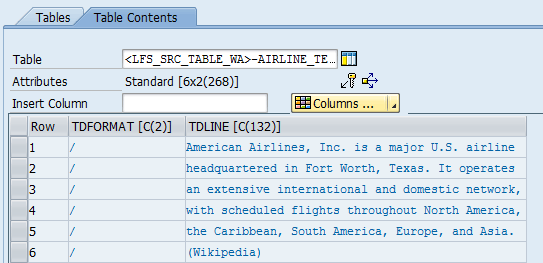
Figure 15
Populated text lines
To store the string conversion, you must first create a new target internal table structure. Figure 16 shows how the components to represent this structure are built. Whenever the text lines element occurs in the source structure, a new string element is created in its place for the target structure.
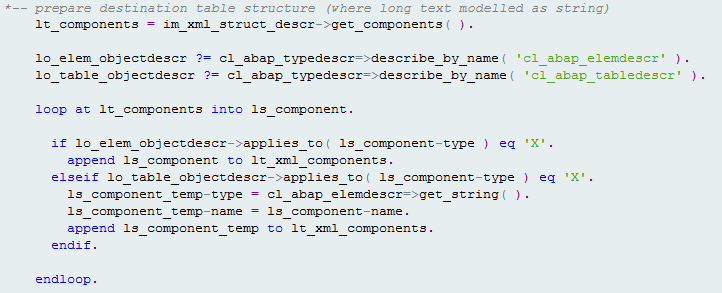
Figure 16
Populating a target internal table data with data from source internal table I
After the target structure has been prepared, you can perform the copy operation. During the conversion of text lines to string, the new string is formed by concatenating each line of text separated by a special line-break constant (lc_xml_newline). This constant contains a line-break character sequence recognized by the SpreadsheetML format (Figure 17).

Figure 17
Populating a target internal table data with data from source intenral table II
After the copy operation, the populated table looks like Figure 18.
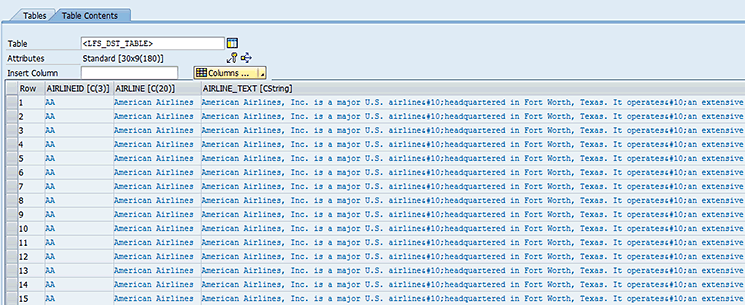
Figure 18
A populated target internal table
3. The third and final change that you need to make is to transform the table into a format that is able to represent the information in an Excel workbook. The populate_xml_document exploits the Document Object Model (DOM) processing capabilities of the iXML library to generate a document that conforms to the schema definition of SpreadsheetML. The call is shown in Figure 19.
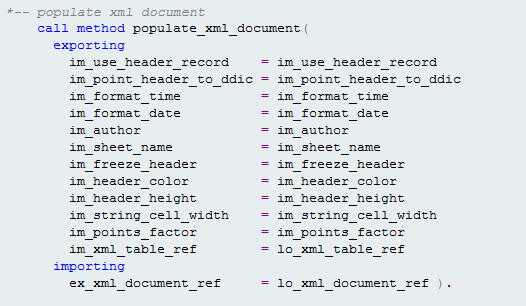
Figure 19
Call to populate the XML document
If you are familiar with the basic concepts of the iXML library and have followed the explanations made so far, there should be nothing that is unusual about the implementation of this method. Instead of focusing on the implementation itself then, I want to focus on the structure of the XML and how it relates to the Excel workbook.
Before I move on to this, I first complete the examination of the factory method by looking at the constructor that is called when it is instantiated. Figure 20 shows there is now an additional parameter (im_xml_document_ref) representing the XML document that has been built.

Figure 20
Constructor for table introspector class
The SpreadsheetML Document Structure
The first line of the document is an XML declaration that represents that the file conforms to version 1.0 of the XML specification. The second line is a processing instruction used to identify that the document is an Excel spreadsheet. Without this line, the document may not associate properly with Microsoft Excel. These two lines are shown in Figure 21.
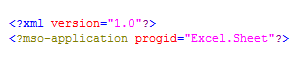
Figure 21
Beginning the XML document
The first element is the Workbook root element. This element declares the namespaces that are used to contain different elements and attributes. For example, the ss prefix declares a namespace that contains elements and attributes related to basic spreadsheet functionality, whereas the x prefix declares a namespace that contains elements and attributes used to describe more complex features of Excel. The first child element of the Workbook root element is DocumentProperties. This element is used to specify properties such as document author (Figure 22).

Figure 22
The namespaces and document properties
The next element is the Styles element. It is used to hold information that formats workbook components. Three main types of styles are created. The first style type is used to format the header. The color applied to this style is set by the corresponding parameter (im_header_color) in the factory method. The second style type is used to format the body (i.e., all rows except the header row). The third style type is used to format each column. These styles can be used, for example, to apply a format based on the type of data found in the column (Figure 23).

Figure 23
The styles
The next element is the Worksheet element. It defines a single sheet in the workbook. The name applied to the sheet is set by the corresponding parameter (im_sheet_name) in the factory method. The first child element under the Worksheet element is Table, which stores elements related to the table, such as columns and rows. Inside the Table element appear a set of Column elements that define column-level properties. Here, styles are applied to each column. In addition the column width is specified in points. The width is calculated based on several factors.
The number of characters to accommodate in a column is based on the length defined in the Data Dictionary for the data type, or the length of the description in the header (whichever is greater). This value is then multiplied by an estimate of the average points per character that can be set by the corresponding parameter (im_points_factor) in the factory method. If the string type is used, there is no defined length in the Data Dictionary, and so in this case, the length can be set by the corresponding parameter (im_string_cell_width) in the factory method. The result looks like Figure 24.

Figure 24
The worksheet, table, and columns
The next element is the Row element. The Row element holds a Cell child element for each cell found in the row. Each Cell element in turn holds a Data child element that is used to specify the type of data stored as well as the data value.
For the header row, the height is set by the corresponding parameter in the factory method (im_header_height). Each data value is set based on descriptions from the Data Dictionary if the relevant parameter (im_point_header_to_ddic) has been set in the factory method (Figure 25).

Figure 25
The header row
For the data rows, the height is set based on the AutoFitHeight attribute. Each data value is set based on the internal table data. The text lines that hold the airline description have been successfully converted into a string and placed in a single cell (Figure 26).
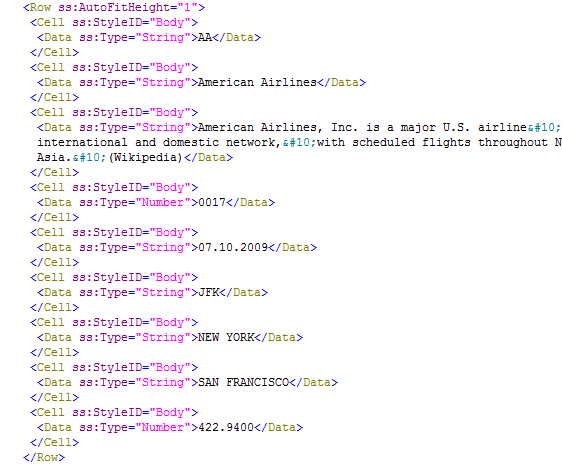
Figure 26
An example data row
The final element is the WorksheetOptions element (it appears after the Table element). This element is used to take advantage of features offered by Excel. In Figure 27, the freeze pane feature is applied to the header row if the corresponding parameter (im_freeze_header) in the factory method has been set.
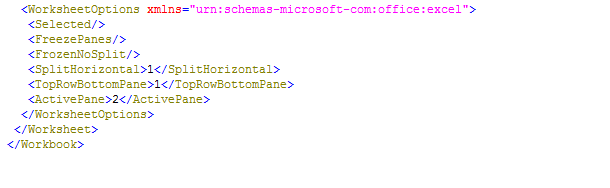
Figure 27
The worksheet options
Calling the Getter Methods
With the table introspector utility class capabilities extended to include support for the SpreadsheetML format, there are now two additional getter methods available. You have already seen the method get_xml_rendition used in the demonstration program. This method uses a table-based output stream to generate an output format that is suitable for downloading to file. The second method is get_xml_solix_rendition. Unlike the first getter method, this method creates an xstring-based output stream that is then converted to a format suitable for use as an attachment to email.
The available getter methods (as well as all other methods) can be seen in the object list for the utility class shown in Figure 28.
Figure 28
Object list for table introspector class
David Duncombe
David Duncombe is an SAP Analyst at Powerlink Queensland. He has more than five years experience as a developer, and specializes in ABAP Objects and SAP NetWeaver Process Integration. He holds an honors degree in information technology from Queensland University of Technology.
You may contact the author at duncombe007@hotmail.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




