
SAP Data Services: How to Extract, Transform, and Load Data into SAP HANA
With the extract, transform, and load (ETL) functionalities becoming native to the SAP HANA platform, the future switch from SAP Data Services (formerly SAP BusinessObjects Data Services) to SAP HANA is inevitable. SAP’s slogan is Run Simple, so the consolidation of this functionality is an especially fitting example of that approach. The emergence and growth of SAP HANA signifies a trend that compels industry experts to remain informed regarding the latest functionality. In this article, I offer insights into the future of ETL on the SAP HANA platform.
I show how SAP Data Services currently integrates with SAP HANA and how SAP Data Services’ future is impacted by the upcoming native ETL functionality that SAP HANA will include, such as smart data integration and smart data quality. In this article, I also cover the latest capabilities of SAP Data Services (version 4.x onward) and how they integrate with SAP HANA (Support Package Stack 9 onward). As of Support Package Stack 9 (released October 2014), SAP HANA offers enhanced capabilities for achieving data integration, data quality, and data streaming. Prior to SAP HANA Support Package Stack 9, SAP Data Services typically served as the primary tool for these tasks on hundreds of projects that required ETL processing of data. Nevertheless, SAP Data Services maintains a considerable role and is not being phased out anytime soon. I examine and explain the future of SAP Data Services in the ETL landscape and how it aligns with the new functionality offered by SAP HANA.
New ETL Services Offered by SAP HANA
As of Support Package Stack 9, SAP HANA offers smart data integration, smart data quality, and smart data streaming. The latest SAP HANA tools now mirror most of the data integration and quality capabilities offered by SAP Data Services. The smart data streaming functionality enables acquisition, investigation, and response to real time event data within the SAP HANA application.
Explore related questions
SAP HANA’s Effect on SAP Data Services
SAP Data Services is a versatile tool for linking a multitude of source and target systems. Furthermore, it offers unlimited scalability and is adept at handling intricate transformations. The benefits of SAP HANA smart data integration and smart data quality are that a cumbersome client application is no longer required and the system architecture has been streamlined. Thus, the latency and performance issues that often occur in SAP Data Services when using remote repositories relative to the development application can be circumvented.
SAP Data Services performance issues were often a result of the time required to extract data from a source system and then load it into a target system. Therefore, the SAP Data Services platform was mainly to blame for poor performance when processing was most needed, such as with data-cleansing tasks. With SAP Data Services as the mediator between the source and target systems, it would often be blamed for slow performance. SAP Data Services is meant for batch loading of data and was never an ideal tool for real-time replication, which is now a feature offered by SAP HANA.
SAP’s recent goal is to simplify and consolidate its tools and applications. By incorporating the ETL capabilities into SAP HANA, which is also where data modeling is done (via SAP HANA studio), more can be done with the same platform, thereby reducing the number of peripheral tools required. Consequently, less hardware is needed, which simplifies implementations, maintenance, and system landscapes. Despite this, SAP is continuing to market SAP Data Services as its premier Enterprise Information Management (EIM) offering. With more than 10,000 organizations in its EIM client base, SAP Data Services has carved out a solid niche in the Gartner Magic Quadrant for data-integration platforms. While SAP will continue to market and support SAP Data Services for the time being, the trend appears toward SAP HANA eventually absorbing the ETL capabilities, ultimately rendering SAP Data Services redundant. Thus, SAP Data Services will likely experience fewer enhancements going forward, whereas extensive augmentation is anticipated with SAP HANA smart data integration and smart data quality.
The Future of SAP Data Services
New implementations that require ETL and that have existing applications running on the SAP HANA platform should opt for the smart data integration and smart data quality approaches rather than SAP Data Services, due to smart data integration and smart data quality being natively available within SAP HANA, which circumvents the additional step of implementing SAP Data Services, saving time and effort. When SAP Data Services is already deployed, there is no need for any change within the near future since SAP’s support of Data Services will continue for the foreseeable future (Figure 1). The SAP Data Services SAP roadmap indicates that mainstream support is in place through 2018, and priority-one support through 2020. SAP Data Services 4.2 is likely to be the most current version of the platform for a while since only bug fixes and minor updates are expected.

As of now (June 2017), SAP has not developed a method to transfer SAP Data Services jobs to SAP HANA smart data integration and smart data quality, and it is unknown whether a process is planned. It would be prudent to monitor the latest SAP HANA smart data integration and smart data quality innovation to facilitate an informed decision about whether to transition from SAP Data Services once these tools are established and mature. Use cases for smart data integration (see Figure 2) include virtual access to data that is not critical (through smart data access); ETL for native SAP HANA data marts and data warehouses; sidecar deployments for OLTP reporting; migration of data from legacy systems into SAP HANA; and batch, federated (smart data access), or real-time integration of external source systems and SAP HANA.
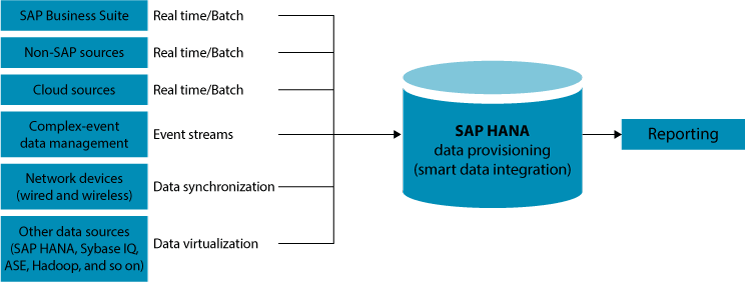
Smart data integration can be deployed on premise or in the cloud. Smart data integration offers data-push replication in real time on designated sources with Change Data Capture (CDC) functionality. This is done on the Sybase Replication Server, which is an established technology. Smart data integration can also pull batch data from any type of source. Smart data access is SAP HANA’s federation platform and is used when remote data is required, such as queries or initial data loads. An adapter Software Development Kit (SDK) is available for extension of smart data access connectivity by smart data integration. If the replication stream is interrupted or stopped, smart data integration can continue processing data. It can also continue to function when there is a short-term disconnection of the SAP HANA target system due to unforeseen circumstances such as system interruptions due to a natural disaster. Smart data integration transformations include virtual and non-virtual SAP HANA tables, as well as views. The Application Function Modeler (AFM) is the SAP HANA studio user interface (UI) for editing transformation flows.
SAP Data Services Connectivity to SAP HANA
Optimized for batch data loading, SAP Data Services offers a platform to load data into the in-memory database on SAP HANA. For real-time data loading, the Sybase Replication Server or smart data streaming can be used. The SAP HANA Modeler creates the primary loading jobs and data flows to load into tables, and uses SAP Data Services to browse and import external metadata. SAP Data Services can be used to edit data flows beyond their initial configuration.
An SAP HANA analytic or calculation view can be used as a source in SAP Data Services if the naming conventions follow the appropriate syntax and satisfy case sensitivity. To achieve this, an import-by-name from the datastore is necessary. Whenever possible, SAP Data Services pushes operations to the source database, which minimizes the number of rows that need to be processed and enables the database engine to perform most of the work. There are several SAP Data Services SQL functions available that can push operations to SAP HANA, and there are equivalent functions in SAP HANA that accomplish the same tasks. A few examples are the Count_Distinct and IfThenEls functions in SAP Data Services, and the Distinct and Case functions in SAP HANA. SAP Data Services can also create SAP HANA calculation views to enhance improvement. There are certain prerequisites for using SAP Data Services to create calculation views for push-down to SAP HANA. They are:
- SAP Data Services calculation views that are internally generated include the Merge, Case, and Query transforms; these are in addition to the SAP Data Services SQL functions. SAP Data Services is designed to create the appropriate SAP HANA calculation views related to the business/ ETL transformation logic whenever possible to leverage the processing power and speed of SAP HANA. Therefore, this vastly accelerates performance and eliminates the requirement to perform the transformation using the SAP Data Services engine prior to loading data into SAP HANA. As such, the business/ETL transformation logic is comprehensively pushed down to the SAP HANA platform, which avoids the comparatively slower processing speed of SAP Data Services.
- When SAP HANA is used as the source database for push-down tasks, application data, other databases, and Web files are initially staged as SAP HANA source tables.
- SAP HANA Support Package Stack 7 or above is required.
Inbound data that originates from relational data sources, Web files, or third-party applications is initially replicated or staged into SAP HANA tables. Subsequently, it is possible to develop business and ETL transformation logic within SAP Data Services to load data into the suitable SAP HANA target system (Figure 3).

When appropriate, SAP Data Services is optimized to create the requisite SAP HANA calculation views for the business and ETL transformation logic, which brings forth the processing power of the SAP HANA database. Consequently, performance is accelerated and the transformations do not need to be performed via the SAP Data Services engine. The SAP HANA system is then loaded with the data. There are cases in which SAP Data Services cannot create calculation views for SAP HANA depending on whether the three previously mentioned prerequisites are met. SAP Data Services performs as much optimization as possible related to any constituent of the dataflow. Calculation views that are created by SAP Data Services do not persist since they cannot be reused externally to SAP Data Services.
SAP Data Services includes a readily scalable engine to transport massive volumes of data into SAP HANA, and is also compatible with SAP HANA’s bulk-load interface. The preexisting data quality transformations in SAP Data Services are available, but require additional licensing. Additionally, SAP Data Services can connect between data or metadata and all popular enterprise data sources. SAP Data Services can natively connect to applications, flat or text files, and relational database management systems (RDBMSs). Support for non-relational data formats such as text and XML is available.
Replicating Data with the SAP Data Services Workbench
The SAP Data Services Workbench is an Eclipse-based UI that features a user-friendly wizard for replicating data or metadata, such as table definitions, from third-party source databases into SAP HANA. The three steps for replicating sizable data sets from the source into the SAP HANA target are:
- Establish connections between source and target systems.
- Select desired (or all) tables from the source system for replication; the target tables are automatically generated.
- Develop and execute the SAP Data Services’ jobs to transport the data with a single click.
Beyond the wizard, additional functionality includes filtering, data mappings for expressions and functions, and delta-loading options. Job execution can be monitored within SAP Data Services to track live progress and historic load times can be compared. To generate a SAP Data Services batch job, take the following steps from the Data Services Designer.
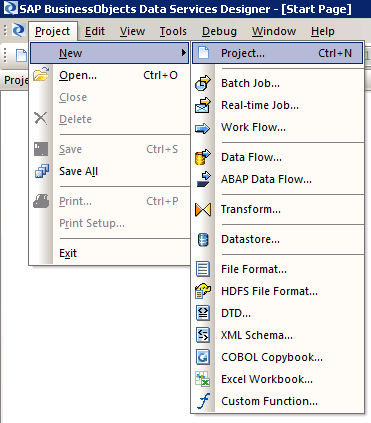
1. Create a new project that adheres to naming conventions by following menu path Project > New > Project from the initial screen of the Data Services Designer, and the screen on the right of Figure 4 opens. Select New and then Batch Job… .
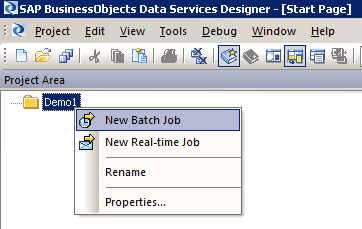
2. This creates a new folder (Demo1), shown in Figure 5. Right-click this new project folder and select New Batch Job from the drop-down options that open (you can also use a right-click to rename this folder with a more descriptive name).
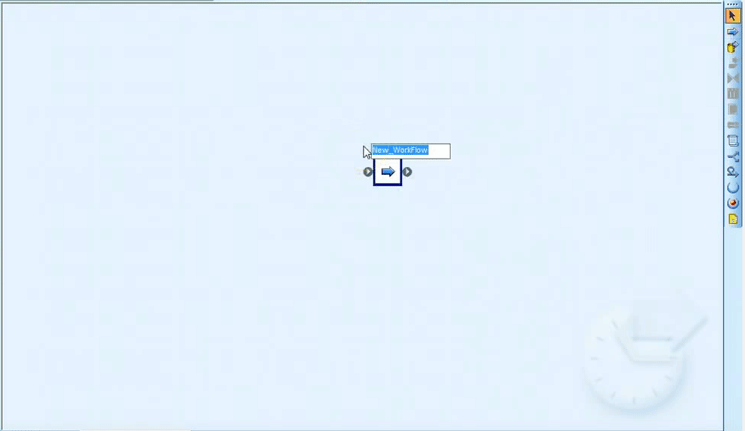
This opens a new modeling screen, shown in Figure 6, where you can load data into SAP HANA using the SAP Data Services functionality.
3. In the screen that opens (not shown) double-click the cell under Mapping.
4. In the context-menu window that opens (not shown), click the Functions… option.
5. In the next screen that opens (not shown), choose the required category and associated function and specify the input parameters of the function.
6. Click the Done button to save your entries.
The Data Extraction/Load Process Options
All standard SAP Business Suite extractors and SAP BW 7.4 ETL processes are supported by BW on SAP HANA, as follows:
- DB Connect
- Flat files (CSV, XLS, and XLSX)
- SAP Data Services 4.x
- Server Application Programming Interface (SAPI)
- Universal Data (UD) Connect
- Web Services
If the SAP LT Replication Server (SLT) is used for direct loading into SAP HANA, then tables are automatically generated. SAP BW is compatible with data that is replicated in real time to SAP HANA via SLT. SLT real-time custom data marts can be joined from the SAP HANA schema with SAP BW data models using Transient or Virtual InfoProviders, Open Operational DataStore (Open ODS) views, and Enhanced CompositeProviders in SAP BW 7.4.
SAP Data Services supports logical and physical partitioning for SAP HANA data extraction. As of SAP Data Services 4.2 Support Package 2, SAP HANA column-store tables that are partitioned by range can have their partition metadata imported by SAP Data Services.
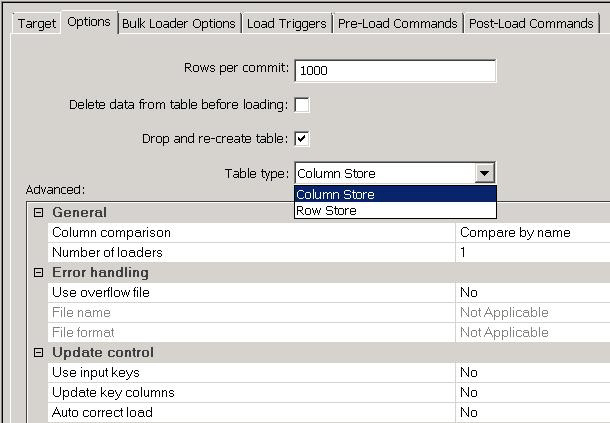
For SAP HANA tables that are not partitioned, logical partitions can be generated per the data. Analogous to physical partitions, SAP Data Services can leverage the definitions of the logical partitions to extract data from SAP HANA in parallel, which enhances data-extraction performance. Moreover, when the source and target tables are SAP HANA tables and necessitate transformation logic, SAP Data Services offers support for range partitions, which assists with the push-down of select commands, data, and insertion of SQL commands between SAP HANA tables. For loading data into SAP HANA, SAP Data Services includes these customizable options for configuration prior to executing a job (Figure 7):
- Rows per commit
- Number of loads
- Bulk-loading options (number of loaders)
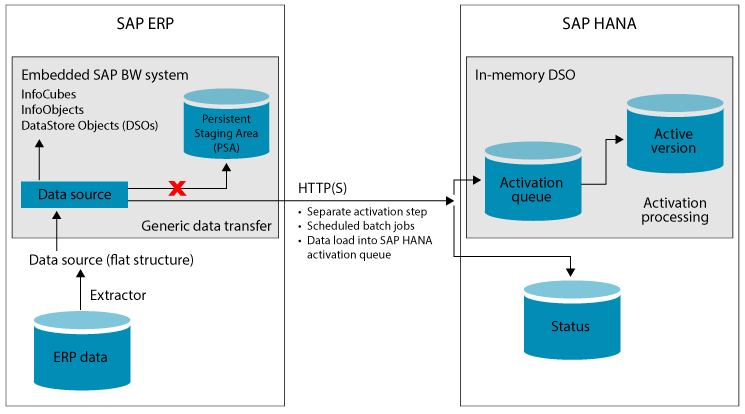
The Direct Extractor Connection (DXC) [head 2]
As discussed in the first article of this series, the DXC (Direct Extractor Connection) is used to extract data from the SAP Business Suite into SAP HANA using standard SAP BW extractors. DXC is designed to leverage SAP BW business content from data sources to reduce complexity of data-modeling tasks within SAP HANA data marts to speed up implementation projects (Figure 8).
The DXC approach also has constraints that should be considered, including:
- If one does not already exist, the data source requires establishing a key field through an associated procedure.
- Minimum system requirements: SAP Business Suite on SAP NetWeaver 7.0 and above with at least release 700 SAPKW70021 (Support Package Stack 19, November 2008)
- Not all data sources are delta-enabled, which is not pertinent to SAP HANA and DXC, but is worth acknowledging.
- Modeling in the embedded SAP BW system is not a component of the DXC option. There is a sidecar option that uses a separate SAP BW system rather than it being embedded (see Figure 9).
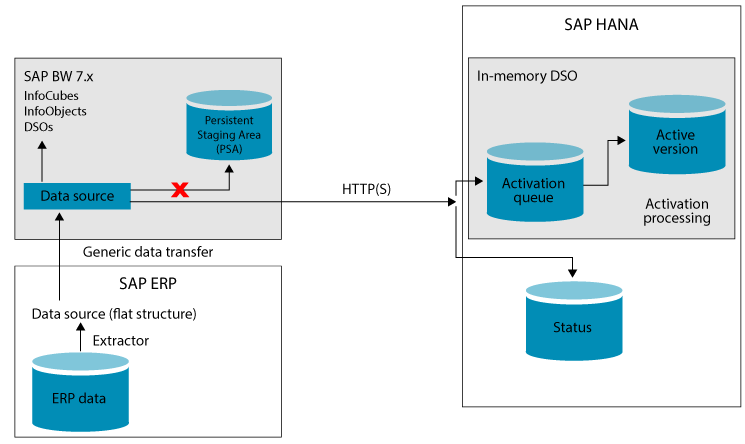
As of SAP NetWeaver version 7.x, SAP BW is a component of SAP NetWeaver ABAP in an ERP environment with ECC 6.0 and above. Therefore, the SAP BW system is an embedded system (see Figure 8). In most cases, SAP BW is hosted on an independent server rather than being embedded on the same hardware. The only features that the default DXC method uses are the scheduling and monitoring capabilities of the embedded SAP BW system. When extracting data with DXC, the typical dataflow is disregarded and data is sent directly to SAP HANA.
The SAP Business Suite system extraction is operated by the data-warehousing workbench within the embedded SAP BW system. Thus, data that is extracted from the SAP Business Suite environment is not loaded into the Persistent Staging Area (PSA) of the embedded SAP BW system—instead, it is relayed to SAP HANA. Once it arrives at the SAP HANA system, the data is loaded to in-memory DSO activation queues and is then activated and linked to the appropriate in memory table. It is worth noting that the data-load monitor of the embedded SAP BW system makes it appear that the data load into the activation queue in the SAP HANA DSO is loading into the PSA of the embedded SAP BW, even though this is not actually taking place.
The Internet Connectivity Manager (ICM) service receives XML packages via the HTTP(S) connection. Within SAP HANA, there is a distinctive run-time component involving a mechanism on the SAP HANA Extended Application Services (XS) engine which receives data packages from the ICM service and adapts their format, inserts the records into the activation queue of the in-memory DSO, and sequences the records that are meant for the active table (activation processing). The ICM service and XS engine must both be activated to use DXC with SAP HANA.
To configure DXC, the main steps are to apply SAP Note 1583403 and follow these general steps:
- Enable the ICM service and XS engine:
- SAP HANA XS engine
- SAP Web Dispatcher Service
- Create an SAP HANA DXC:
- Apply the SAP Notes per the installation guide
- Define the DXC connection within SAP HANA
- Import the delivery unit
- Configure the XS application server for use with DXC
- Confirm that the DXC is functioning
- Define user account and schemas within SAP HANA studio
- Generate the HTTP(S) connection to SAP HANA in SAP BW
- Configure the data sources in SAP BW to replicate the structure of the SAP HANA-defined schema
- Load the data into SAP HANA using an InfoPackage from SAP BW
How to Load Spatial Data into SAP HANA with SAP Data Services
SAP Data Services supports spatial data such as point, line, polygon, collection, or heterogeneous collections for reading and loading into SAP HANA. When a table with spatial-data columns is imported into SAP Data Services, the spatial-type columns are imported as character-based large objects (CLOB). The columns contain an attribute known as the native type, which includes the value of the actual data type in the database (e.g. ST_GEOMETRY).
The limitations of loading spatial data into SAP HANA include the fact that creating template tables with spatial types is not supported due to the CLOB format. In addition, spatial data cannot be modified within a data flow because the spatial-utility functions are not supported. To load spatial data from Oracle or Microsoft SQL servers to SAP HANA, follow these steps:
- Import the source table to SAP Data Services from the Oracle or Microsoft SQL server
- Generate the SAP HANA target table with the desired spatial columns
- Import the target table into SAP Data Services
- Develop a data flow with an Oracle or Microsoft SQL server source as the reader and include required transformations
- Add the SAP HANA target table as the loader and ensure that the spatial columns data type is not modified within the transformation.
- Create an SAP Data Services job with the data flow and then execute it to load the data into the target table
You should now have a thorough familiarity with the capabilities of SAP Data Services as it pertains to the ETL landscape and the popular SAP source and target systems to which it can connect. Going forward, I recommend monitoring the updates that are released for SAP Data Services while simultaneously keeping track of the enhancements being introduced to SAP HANA smart data integration and smart data quality, which represents the future of ETL functionality. Doing so will help you make an informed decision about which approach to undertake, and whether a transition from SAP Data Services to SAP HANA smart data integration and smart data quality would be an appropriate step within the next few years.


