Step beyond traditional database tuning concepts, such as indexing and partitioning, and get expert tips to move toward a parallel approach for code design and job construction. Examine parallel execution within SAP Data Services to see how it distributes operations and uses the strengths across your system. Get expert advice on leveraging the pushdown capabilities delivered with SAP Data Services, including how to properly distribute logic and optimize performance.
Key Concept
SAP Data Services is SAP’s data integration and data quality solution that offers many different opportunities for tuning and scaling ETL code. Traditional database tuning should be the foundation of ETL development with SAP Data Services, but efforts should not stop at the database. Concepts such as breaking logical order, thinking in parallel, and a solid understanding of SAP Data Services features including caching, bulk insert, and Data_Transfer are crucial components for tuning the ETL code outside of the database.
Performance and tuning are constants that every developer must confront and reconcile on a daily basis. A common scenario surfaces in almost every organization: The business strives to increase functionality that in turn increases logical complexity, yet a load window never increases with these demands. The business may be working to increase measures or key performance indicators (KPIs). There may be a huge data volume increase due to recent data integration, or the organization may have an advanced business intelligence (BI) strategy with master data operations that globalize aspects of the business requiring expensive processing timelines. All these scenarios increase complexity and load times. The key point is that as BI strategy evolves, doing more processing in less time becomes inevitable. This is why performance tuning strategies are some of the most important design considerations throughout the BI life cycle.
Proper extract, transform, and load (ETL) performance is not an accident, nor is it something that just occurs without thought and planning. SAP Data Services on its own can assist with realizing performance gains. However, to be truly successful you must consider performance objectives in the design through the life cycle of the project. In this article, I frame my discussion around using SAP Data Services for maximum performance. Through examples, I demonstrate best practices in designing high performing ETL code. I’m assuming you have familiarity with ETL concepts and knowledge of the SAP Data Services platform.
Note
SAP Data Services was formerly called SAP BusinessObjects Data Services.
There Is a Logical Order, Now Break It
When approaching ETL code design, the logical order of execution is an important concept that always plays into any discussion in system design. Take the example of loading a sales data model. There is a logical order that is present and required to meet the constraints of the physical data model, thus dependent subjects must be loaded before parent subjects. For example, address data must be loaded before customer data and customer data must be loaded before sales data. An address must be present for a customer to inherit the address and a customer must be present for a sale to inherit the customer. This is the logical order and it is dictated by the physical database constraints that provide referential integrity to enforce this logical model.
However, database constraints enforce this integrity record by record. This is an inefficient way to approach this problem for batch-based ETL work. This approach is fine for an online transaction processing (OLTP) system, as the transactions are committed one record at a time. In ETL, a transaction is usually a batch that could be any number of records. For instance, processing 100,000 records row by row at the database results in longer runtimes and inefficient processing. When possible for batch ETL, enforce these checks through validation transforms and error logs in SAP Data Services. By capturing records into an error log table using an SAP Data Services Validation transform, you can effectively bypass the database constraints, but still record all failed records as errors. See the data flow in Figure 1 illustrating proper use of the validation transform.

Figure 1
Validation transform takes the place of a database constraint
In the data flow in Figure 1, the qry_Lookup transform looks up the foreign key of the customer record in the FACT_SALES target table. If the customer record is not found in the FACT_SALES table, then the error value is trapped and the Validation transform passes the record to the Fail path. This results in writing an error record to the ERROR_LOG table in the target database. The Validation transform controls the flow of the records sending the failing records to the error log, thus restricting the records from FACT_SALES. This example illustrates the ETL process owning and enforcing the constraints. This method allows the developer more flexibility with caching options in the lookups and compares as opposed to a record-by-record approach of the database. Since the ETL can own the validation comparison, rules may also be enforced in bulk, resulting in many more tuning options, such as running this data flow in parallel with other operations to increase performance.
Now examine the lookup_ext function nested in the qry_Lookup query transform, illustrated in Figure 2. The error variable value ($G_ERR_INT_RI) in the default field is what controls the flow of the data in the validation transform.

Figure 2
The error value in the Default field is returned to the variable $G_ERR_INT_RI in the lookup function inside of the query transform qry_Lookup
This design performs two important services for the ETL job:
1. The Validation transform bypasses the need for database constraints
2. Error reporting is effectively captured in the error log table
This error validation design allows for the physical database constraints to be dropped before the subject areas load in the ETL code. With proper caching options, this helps the performance for the SAP Data Services job, but more importantly paves the way for parallelization in the design to dramatically increase the performance of the job.
Think in Parallel
Since the logical data constraints have been met using the Validation transform in the data flow, it is now time to break the logical barrier by thinking in parallel. In the sales data model example cited above, logical order no longer matters after the physical database constraints have been removed. The validation in the data flow design has preserved the integrity of the data. Now you can load the subjects of Address, Customer, and Sales at the same time. See Figure 3 to illustrate parallel data flows.

Figure 3
Parallel data flows loading subjects concurrently
In this design, all data integrity is intact, and now you can think in terms of covered operations. A covered operation is a data movement that is covered from a time perspective by a longer-running operation. In the example in Figure 3, a typical customer load may have 50,000 records but the sales detail may comprise more logic and be four times as large, say 100,000 records. If customers load in five minutes, addresses in another five minutes, and sales in 10 minutes, a sequentially loaded operation is a total of 20 minutes. See the detail in Tables 1 and 2. By using covered operations and parallel loading techniques, you can cut your data load time in half. This is a significant reduction and something that is not achievable by database tuning alone.

Table 1
Sequential loading

Table 2
Parallel loading
Performance Tips: Cache, Bulk Insert, and Data Transfer
All the examples so far have been focused around data flow and job design, but there are specific features in SAP Data Services that you cannot overlook to achieve maximum performance. Features such as cache options in lookup functions, bulk options for table loaders, and Data_Transfer transforms all contribute greatly to increasing performance in SAP Data Services jobs.
Cache Options in Lookups
SAP Data Services is designed with the idea of stratifying the work load between the job server and the source and target database. It is important to consider how comparison data for expensive operations, such as lookups, should be cached. A cache in SAP Data Services stores the data temporarily in memory to speed iterative reparative operations, such as lookups. To decide whether data should be cached, you should ask questions such as:
- Should you cache the entire table?
- Should you not cache any data?
- Should you build a cache as a demand load operation?
- Should you cache a subset of the data in the table?
The Cache spec options reside within the Lookup_ext function, and the location is illustrated in Figure 4.

Figure 4
Cache spec options in the lookup_ext function
Cache the whole table using the Cache spec option PRE_LOAD_CACHE to provide a great boost in performance. This option is best used when the table is 250,000 rows or fewer. After the table is stored in the cache, the lookup performance tremendously increases, as all iterative operations are in memory at this point. This is performed by selecting the PRE_LOAD_CACHE option from the Cache spec drop-down menu in the screen in Figure 4.
It is important to illustrate that the table size is only one side of the equation on whether to cache a table. Consider the time that it takes SAP Data Services to build the cache. Take the following example: If it takes two minutes to build a cache of 200,000 records, but you are only processing a delta of 60 changed records in the data flow, it is likely that not caching the table is faster. Lookups are iterative either way, but performing 60 trips to the database against 200,000 records is likely faster than building the cache in this case. This is an example when not caching the lookup table performs better and uses the NO_CACHE option from the screen in Figure 4. The final option of DEMAND_LOAD_CACHE is used when you build the cache while the lookup operation is running. The classic example is a US state column in a 1,000,000-record detail table. The DEMAND_LOAD_CACHE builds state values into the cache in memory as the values are seen, but after all US 50 states are built, the lookup occurs in memory just as a cached lookup.
One more use case to consider with lookup performance is whether to cache a subset of data in the table. This is done two ways: First, select the PRE_LOAD_CACHE option in the screen in Figure 4, then use the Custom SQL button to generate custom SQL as shown in Figure 5.
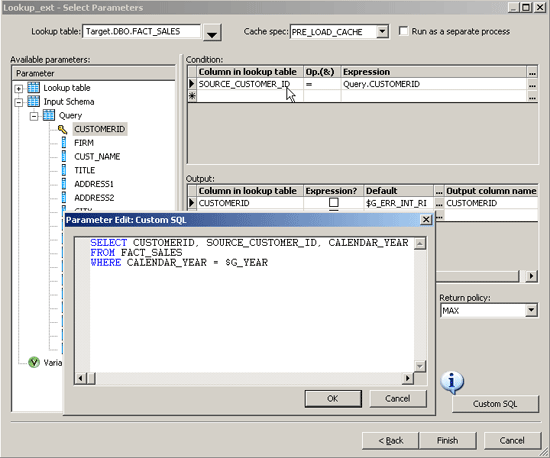
Figure 5
Use Custom SQL to select only a portion of the lookup table to increase the Cache spec. options
When you use custom SQL, you essentially create a WHERE clause for your lookup to only cache the portion of the table that you need for the lookup. Take, for instance, a table that is partitioned on calendar year. The table may have 10 years of data, but you may only need current-year data for your lookup. By specifying the lookup to use only data from the current calendar year, you only cache a subset of the table. This is particularly helpful with large tables. Notice in Figure 5 that the Custom SQL button has an information bubble alerting the user that there is SQL limiting the scope of the lookup.
Tip!
When using Custom SQL, include all fields in the SELECT statement that are used in the Lookup_ext function.
Bulk Insert
Bulk operations have been a mainstay in ETL for many years, and they should be exploited whenever possible. Bulk operations provide a means for bypassing database logging in most cases, and large record sets appreciate the added performance gains. SAP Data Services takes advantage of bulk loading APIs in the following databases:
- DB2 Universal Database
- Informix
- Oracle
- Sybase ASE
- Sybase IQ
- Teradata
- SQL Server
I’ll focus on SQL Server options in this article.
Take note in the Bulk Loader Options tab in Figure 6 of the four parameters that are available for SQL Server bulk loading:
- Mode
- Rows per commit
- Maximum rejects
- Network Packet Size in kilobytes
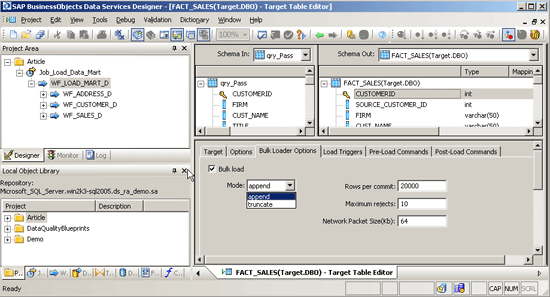
Figure 6
Bulk Loader options (for SQL server) for the FACT_SALES target table
The Mode parameter exists simply to select either appending to the existing table, or truncating the data first, then appending new data. The Maximum Rejects parameter sets the threshold for the maximum number of violations that can occur against the target table before the job fails. The Rows per commit and Network Packet size parameters are the two most important options from a tuning standpoint. These two parameters must be used together to get the most performance out of bulk loading SQL Server. A good rule for Rows per commit is to set blocks of 20,000 records for a baseline. You can also set the Network packet size to accommodate the size of the data to fill the network packets as densely as possible with each transmission. I have seen good results with a 64 kilobyte network packet size. Start with these values and test with your data.
Tip!
Make sure to maintain the same size load and ideally retest with the same data to ensure accurate results on your network with your data.
Data_Transfer Transforms
The Data_Transfer transform is useful for performance tuning by increasing pushdown capabilities in SAP Data Services. As mentioned earlier, SAP Data Services strives to distribute the workload across the source and target databases as well as the SAP Data Services’ job server. Data _Transfer transforms increase these options by attempting to push the work down to the source databases. Consider the following example: Sales records need to be extracted as deltas for only changed customers from the source system. With a Data_Transfer, this can easily be accomplished in the same data flow.
In the example in Figure 7, changed customer records are selected from the USA_CUSTOMERS table in the Source system by using a WHERE clause in the qry_Changed_Customers query transform, then the Data_Transfer creates a temporary table of this result set at runtime in the Source database using the Source data store connection. In Figure 8, you can see the settings needed to configure a target table in the Data_Transfer transform to receive data. To reach this screen inside the Data_Transfer, double-click Data_Transfer and all the settings are available on the General tab.
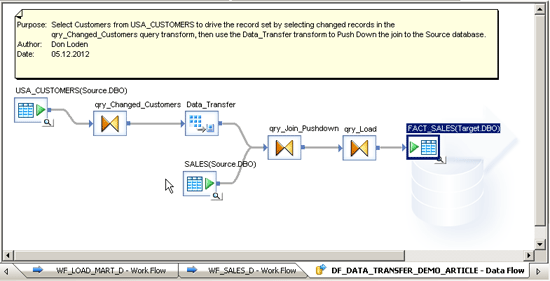
Figure 7
Using Data_Transfer transform to push down work to the source database

Figure 8
Configure your target table
Notice in Figure 8 that the Table name field references the Source data store. This is particularly important because it allows the pushdown of the second join in the query transform qry_Join_Pushdown. The Data_Transfer transform is joined to the Sales table in the Source data store, so this join is effectively pushed down to the Source database in SQL Server and the result set is returned to the job server to continue. Without the Data_Transfer, the whole result set of the Sales table would have been cached on the job server. This would not be a good result if the Sales table has millions of records. This design performs well and is incredibly scalable.
These techniques are not an end to the performance tuning conversation using SAP Data Services. These are production-tested solutions to both start a conversation about tuning and move beyond traditional database tuning. Now the tuning efforts can focus on tuning the ETL code.

Don Loden
Don Loden is an information management and information governance professional with experience in multiple verticals. He is an SAP-certified application associate on SAP EIM products. He has more than 15 years of information technology experience in the following areas: ETL architecture, development, and tuning; logical and physical data modeling; and mentoring on data warehouse, data quality, information governance, and ETL concepts. Don speaks globally and mentors on information management, governance, and quality. He authored the book SAP Information Steward: Monitoring Data in Real Time and is the co-author of two books: Implementing SAP HANA, as well as Creating SAP HANA Information Views. Don has also authored numerous articles for publications such as SAPinsider magazine, Tech Target, and Information Management magazine.
You may contact the author at don.loden@protiviti.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




