Learn how to set up business continuity in SAP HANA with high availability, disaster recovery, and backup/restore concepts. This overview shows the challenges of managing SAP HANA-based applications in the data center.
Key Concept
In thinking about high availability (HA) and disaster recovery (DR) in SAP HANA, you need to distinguish between planned and unplanned outages. Planned outages are maintenance tasks, such as upgrades, patching, and testing, for a graceful takeover in a high availability scenario, or simulating a breakdown and starting again from scratch with a restore. Unplanned outages are the other aspect to cover: a disk fails, a user error leads to a data corruption situation, a power cable is accidentally pulled, or a fire happens in the data center, to mention just a few examples.
Business continuity planning in SAP HANA needs to consider the whole stack in the data center. From top to bottom, that includes the SAP application (both the ABAP application server and the SAP HANA database), the operating system (OS), the file system, drivers and firmware, hardware components, and the network. All of them tend to have dependencies on release levels between each other.
SAP HANA usually is delivered as an integrated solution: a combination of hardware and software. Sometimes it is called an appliance. It still cannot be treated like a toaster. Buy, unpack, plug it in, never read a manual, flip a switch, and it works. If it is broken, throw it out and buy a new one. Not so with a computing device running a business-critical application in IT.
To take the appropriate actions in IT to ensure business continuity, it is essential that two questions be answered by the application departments. First, how much data can be lost in case of a problem and, second, how much time is allowed before work can continue (i.e., the application is available to the end user again).
In more technical terms, the recovery point objective (RPO) and the recovery time objective (RTO) must be defined. As depicted in
Figure 1, the possible time gaps in terms of data loss on the left (e.g., the last save point with data written to disk) and the detection of an error, and then the time until the recovery is complete and the system is operational again after a performance ramp up, needs to be specified by the business functions.

Figure 1
Defining business continuity requirements
I have experiences with companies that can live with several hours as the answer to both questions, especially when the SAP application is not of a transactional but rather of an analytical nature. On the other hand, many corporations request that RPO be at zero, meaning that no data is allowed to be lost, but are not worried about RTO taking one or two hours.
High Availability (HA) Solutions
An SAP HANA-based application (within one data center location) is protected from a failure of a node due to, for example, an issue with the hardware, by an HA concept. An auto-host failover mechanism is desired, with no manual intervention necessary to let the application continue to work.
An SAP HANA system can either run on one server, which is referred to as a scale-up architecture or as a single node, or multiple servers can be combined, which is called a scale-out cluster. Here the single physical system is called a node.
A single node system allows for automated failover using SAP HANA system replication in combination with, for example, the SUSE Linux Enterprise Server (SLES) HA framework. Here one active and one standby server (also known as 1+1) are set up. If SLES is the OS, SUSE provides a framework that can be used in conjunction with SAP HANA system replication to customize the failover functionality.
A good source for more information can be found here:
https://www.suse.com/company/press/2015/suse-enhances-its-high-availability-capabilities-for-sap-hana.html.
Figure 2 shows an example of a 1+1 single-node setup. On the left is the active production system and the standby system is on the right. Both servers are the same size in terms of number of CPU cores and amount of main memory. They are typically located in the same data center and are connected via a 10-Gb Ethernet connection. The components of the SAP HANA in-memory database, such as the index server process, the statistics server process, or SAP HANA studio, are running on the server. The data in memory is regularly saved on the persistence layer, which contains the data files and log files on the internal storage, on which, in my example, the file system IBM General Parallel File System (IBM GPFS) is running.
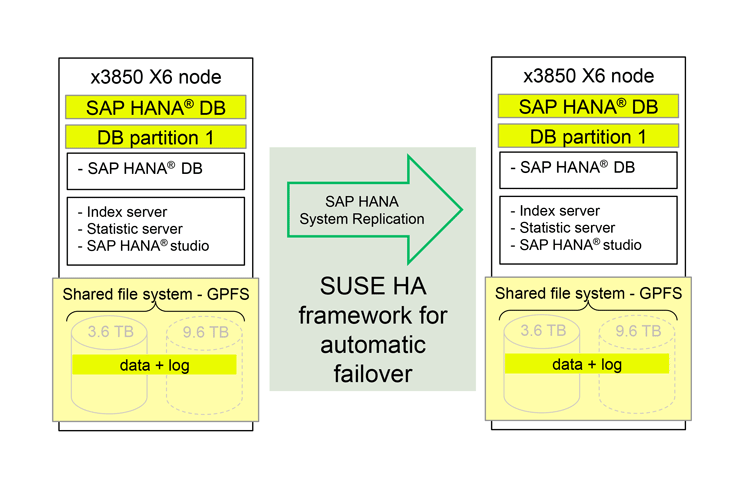
Figure 2
Single-node high availability setup
If SAP HANA is installed on a scale-out cluster, IBM GPFS as a clustered file system for SAP HANA has the automated HA functionality built in already. Multiple active nodes and one standby node cover the desired functionality. In case of a failure of one node in the cluster, SAP HANA, in conjunction with the GPFS cluster design, automatically activates the standby node, loads the necessary data of the failed node from the file system into memory, and continues to work without disruption of service.
The data needs to be loaded from the internal disk into memory. This can involve some delay for the transactions in flight, but no data will be lost. An example cluster with this functionality looks like what is shown in
Figure 3.

Figure 3
Cluster high availability setup

Here you see a four-node cluster: three worker nodes (node 01, 02, and 03) and one standby node (node 04). In the lower part you can see the shared file system as well as two replicas of the SAP HANA data and logs that are stored on internal disks. The first replica shows the data and log for the first three nodes, and a second replica is stored in stripes across the other nodes. In case of a failure of one of the worker nodes, the standby node 04 is automatically activated. It takes over the data, log, and workload from the failed node.
Disaster Recovery (DR) Across Two or More Data Center Sites
To recover from a complete failure of one data center location, say through a fire, flood, or other disaster, a secondary location needs to host a similar system with the same data. This is, of course, to protect data in those unlikely events. Therefore, the measures to be taken need to be balanced in terms of cost and effort versus the business needs. Most companies allow a manual switch from one data center location to the secondary system so no automatic failover in a DR scenario is required.
Option One: Backup/Restore
The simplest approach is to use the backup/restore mechanism. There are two identical setups in both data center locations irrelevant of the distance or latency between the two. You run production in the primary location and run non-production (e.g., quality assurance) at the remote site. Obviously, production data in SAP HANA needs to be backed up on a regular basis. SAP HANA does not differ in that respect from any other disk-based databases in the SAP ecosystem and the same rules apply, as follows.
- Perform regular backups of data/log/OS
- Don’t save the backups in the SAP HANA system, but move them to a dedicated external back-up device
- Have a schema in place about how many backups to keep: daily, weekly, or monthly
- Perform regular tests to restore a system
Transfer the backup files over the network (ftp) to a storage connection or (in the worst case) send a tape or external disk by courier to the remote location. In case of a failure of the production instance in the primary location, use the most recent backup of the production system. Verify the files to be restored, for size and time stamp. Stop the non-production instance running on the remote site, and perform a restore to the environment there. This is quite a worry-free procedure, given that it is tested on a regular basis.
Backup/Restore Procedure Using Snapshots
Backups can be performed in multiple ways. You can use, for example, the SAP BACKINT interface and integrate the processing in a third-party backup tool (details are listed in SAP Note 1730932). Or you can perform data and log segment backups manually.
One way to perform regular backups without interfering with the ongoing database service is to use file system or storage-based snapshots in conjunction with SAP HANA snapshots. Specifically, I describe the procedure using the example of an SAP HANA cluster setup using IBM GPFS as a file system.
First, you prepare a storage snapshot in SAP HANA studio. This is done in the graphical user interface (GUI) under the menu item Backup under the System ID. Right-click Backup and select Storage snapshot. Select Prepare and provide a snapshot name. A reasonable example would contain the date and an identifier.
Then you execute an IBM GPFS snapshot once on any of the nodes in a cluster and log onto a command line window. Enter the following:
# mmcrsnapshot sapmntdata <snapshotname>
To create a meaningful name of the snapshot I recommend you use this:
`date +%F--%T` for <snapshotname>
The result is a new subfolder <snapshotname> in /sapmnt/.snapshots. This subfolder contains all the files that you can then use to copy to a safe place on a different server. Normally this would be the standard location for backup for all applications running in the data center.
When you have created the subfolder, go back to SAP HANA studio and click Confirm in the dialog box of the Storage snapshot window. With that the snapshot is complete and available. The Lenovo solution uses internal disk storage for the persistence layer in the compute nodes. Hence the saved data and log files need to be transferred off the nodes by a copy to an external device that holds the backup data.
For the restore process the SAP HANA instance needs to be stopped. Copy the snapshot data (including subfolder and files) from the external device to /sapmnt/data/<instancename>. You need to ensure that the permissions on the snapshot files are set correctly. The file owner needs to be the database administrator (user: <sid>adm, group: sapsys).
Next, in SAP HANA studio, right-click the SAP HANA instance and trigger recovery of the database to a specific data backup. Select Snapshot and complete the process by clicking Finish. After the restore completes successfully, the procedure automatically restarts the SAP HANA instance. Using this snapshot approach to get a current, consistent set of SAP HANA production data is also a neat way to get valid data for SAP HANA development or education landscapes.
Option Two: Replication
More elaborate are concepts that involve a replication mechanism from the primary to the secondary site. Again, the system setup in both locations needs to be identical. Data replication can be done either synchronously or asynchronously.
Synchronous Replication
Historically, before SAP HANA system replication was available from SAP (before Support Package Stack 5), the hardware vendors had options to provide replication mechanisms. Those methods are called storage replication because they happen on the storage level (not on the system level). Some hardware partners provided a synchronous method to replicate the SAP HANA-related data from a primary site to a remote data center.
Over time, SAP HANA system replication became more mature and now is commonly used for both single-node (scale-up) implementations as well as scale-out clusters. Synchronous replication writes the data and log information to both data center locations, to both systems at the same time, and waits for the completion message from the remote site when the data is persisted on disk.
Asynchronous Replication
If the secondary site is too far away or the network connection and the involved latency between both sites do not allow using a synchronous method, asynchronous replication needs to be considered. This option automatically involves potential data loss. The primary location cannot wait until it is ensured that the data was persisted on disk on the remote site. Hence RTO cannot be zero. Asynchronous replication is usually only considered if the data center locations are far apart—for example, some hundred or thousand kilometers or miles.
Latency Requirements for the Network Connection Between Two Data Centers
When the RTO and RPO requirements are defined and the planning for the architecture starts, a common question is: What is required in terms of latency for the network connectivity between the two data center locations? SAP expresses that in: LOG_WRITE_WAIT_TIME must not exceed 2.5 milliseconds.
Here is the dilemma. This value can only be measured when the SAP HANA system exists in both locations and then it is probably too late to change the architecture. For planning purposes I recommend a simple rule-of-thumb approach that can easily be performed before any SAP HANA systems are installed.
Execute a ping from one server in the primary data center to a server in the secondary data center. Take the result and calculate twice the ping latency plus 0.3 milliseconds. The result must be less or equal to 2.5 milliseconds.
2 * ping latency + 0.3 ms ? 2.5 ms.
In
Figure 4, the average ping latency is 0.148 milliseconds, which would be a sufficient value for a synchronous replication scenario.
2 * 0.148 + 0.3 ms = 0.596 ms

Figure 4
Example of ping latency
If there is a dedicated wide area network (WAN) link between both locations this is a realistic figure. Of course you need to judge the additional traffic coming from other applications running in the IT landscape on the network. This is very dependent on the individual company setup.
For a single-node application (e.g., SAP ERP on SAP HANA), which requires HA in data center one and a DR site in data center two, you should use a scenario that covers automatic failover within data center one (using the SUSE HA framework) and a manual takeover in case of a disaster in data center two. That combines both concepts together and the landscape would look like what is shown in
Figure 5. The blue boxes symbolize data center locations, with the primary location on the left and the remote location on the right.

Figure 5
High availability within data center 1 and disaster recovery in data center 2
If enhanced data security or special compliance requirements have to be fulfilled, then data encryption needs to be in place. The file system IBM GPFS provides that built into the product without further dependency on third-party products (NIST SP 800-131A encryption compliance, including FIPS 140-2 compliant mode). This can be especially helpful for financial institutions or the pharmaceutical sector.
Summary
It is possible to provide business continuity and data protection for SAP HANA-based applications as described. Make sure that the necessary processes are integrated in the established classic IT landscape. As usual, well-designed, planned, and tested processes ensure the right availability of a real-time functionality of SAP HANA for the application departments.

Irene Hopf
Irene Hopf leads the Center of Competence for SAP Solutions at Lenovo globally. She has more than 20 years of experience in the SAP customer space with infrastructure solutions. In this context she is recognized as a thought leader and gives trusted advice for large-scale customer implementations for the integration of services, hardware, and software supporting SAP implementations. Irene would like to thank Martin Bachmaier, lead architect for SAP HANA, Lenovo, and Dr. Oliver Rettig, senior technical staff member, Lenovo, for their help on this article. Lenovo provides infrastructure components and technology services for SAP HANA and all other SAP application components. The key characteristics are value for money, robustness, investment protection, and breadth and depth of SAP solutions expertise.
You may contact the author at
SAPsolutions@Lenovo.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the
editor.



