/HANA
Now that most of the core SAP Business Suite applications have been enhanced to run on SAP HANA technology, many ABAP developers are left wondering how this transition might affect them in their day-to-day development tasks. This article shows how the advent of SAP HANA technology marks a return toward data-centric design principles.
Key Concept
For years, limitations in the database tier have restricted the way that applications are developed in the SAP Business Suite. Now that the latest releases of SAP Business Suite applications are equipped to run on the SAP HANA database, developers confront fewer boundaries. Altering your approach to application design allows you to capitalize on the innovations offered by HANA.
SAP has delivered on its promise to enable the underlying technology stack of the SAP Business Suite to run on the SAP HANA database. This delivery represents a watershed moment in the history of SAP software, ushering in a new age of application development in which data is literally at our fingertips. However, to harness this data, you need to refine your development approach. In this article, I’ll shed some light in this area by describing how the arrival of HANA technology signals a shift (back) toward data-centric designs.
Function Dictates Form
To appreciate how HANA technology changes the way that applications are developed in the SAP Business Suite, let’s take a brief look back at some history. Since the release of SAP R/3 and its three-tier architecture in 1992, conventional wisdom in the ABAP development space has been to develop applications that minimize their use of the back-end database. Why? The short answer is that because the database has represented the primary bottleneck in the performance of SAP NetWeaver Application Server (AS) ABAP-based systems, ABAP developers have been asked to do their best to be good stewards of database resources. In general, this implies that you:
- Avoid the use of complex SQL JOIN statements and nested queries against large tables because this can tie up precious database processor threads. Instead, the preference is to collect the raw data into internal tables on the ABAP side and then crunch the data from there.
- Avoid the use of aggregate functions in SQL statements (e.g., SUM() and MAX()) against large tables because these are tasks that can be performed in the ABAP layer.
- Offload large data processing jobs to background processes and downstream systems such as SAP NetWeaver BW, SAP Supply Chain Management, SAP Advanced Planning and Optimization, and so forth to reduce traffic on the system database. Any requests for real-time reporting on large datasets are summarily rejected or ignored.
For the most part, this design philosophy is all about function dictating form. Because the database historically is the one element of an SAP NetWeaver AS ABAP system that cannot be scaled, developers have been asked to come up with ways to reduce the load on the database wherever possible. Figure 1 shows how data processing responsibilities have been shifted from the database tier into an ABAP application server tier. This isn’t so much about good design practices as it is about making the best out of some challenging technical limitations. You can solve a lot of problems by moving data processing tasks over to an ABAP application server tier that can be scaled out across many SAP NetWeaver AS ABAP instances with lots of CPU cores and memory to burn.
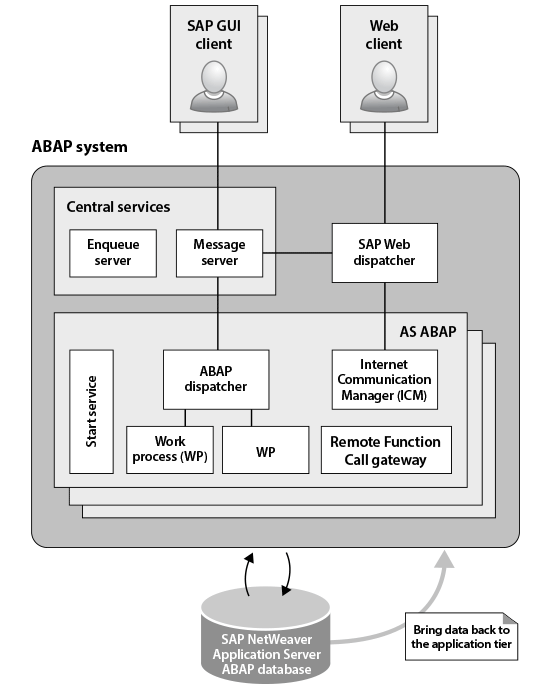
Figure 1
Architecture of SAP NetWeaver AS ABAP systems
Eliminating the Database Bottleneck
Today, HANA technology essentially removes the bottleneck that used to exist between the application tier and the database tier. Now, ABAP developers don’t have to worry so much about overtaxing the database with expensive queries. The HANA database is a workhorse that can be (and has been) scaled to process massive amounts of data in real time.
What does all this mean for ABAP developers? Well, nothing and everything. Because the HANA database is fully SQL compliant, it is possible to continue to use it just like any other database connected to an SAP Business Suite system (e.g., Oracle database, Microsoft SQL Server). Therefore, you can migrate legacy applications without any issues and can gradually adopt some of the more advanced features of HANA technology over time. However, with all the features that HANA offers, you should incorporate them into your application designs.
Refactoring Application Designs
Getting the most out of HANA technology requires a shift in mind-set. You must approach database operations with an open mind, considering all the alternatives. It’s important to bear in mind that the database is usually going to be much more efficient in processing data. For example, no matter how elegant your merge algorithms might be in ABAP, you never come close to matching the performance of the HANA database kernel. After all, it was designed from the ground up to do this kind of data crunching and it’s good at it. Plus, all things being equal, performance is always better if you can avoid transmitting unnecessary data over the wire back to an SAP NetWeaver AS ABAP application server.
For the most part, this change in mind-set doesn’t require radical changes in ABAP programs from a technology perspective. Indeed, you can use many of the advanced features of the HANA database just by dusting off some of those lesser-used SQL statements lurking on the periphery. Table 1 demonstrates some of the ways that you can leverage HANA functionality in your ABAP program designs. This list is in no way comprehensive, but it should provide you with a sense of how HANA technology changes the way that you approach data-intensive operations.
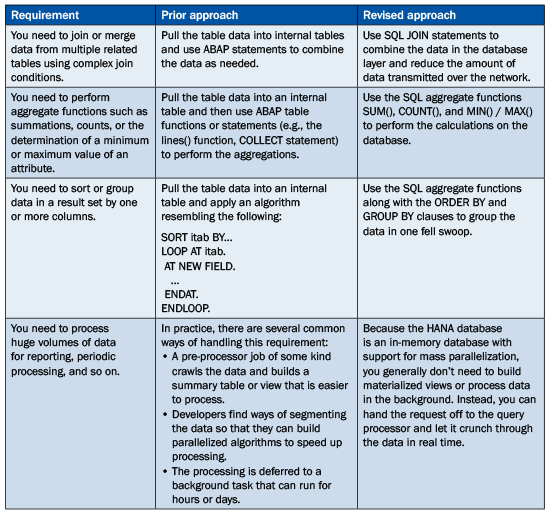
Table 1
Compare and contrast design approaches with HANA
Pushing the Envelope
Looking at the scenarios illustrated in Table 1, you can see that you can achieve a significant improvement in application design just by expanding the use of Open SQL statements. However, to be able to tap into some of the more advanced features of HANA, you have to step slightly outside your Open SQL comfort zone. At first, this may seem a little scary because most developers have been warned repeatedly of the dangers of using native database features. On the other hand, when you consider how infrequently organizations switch databases in an SAP system landscape, perhaps these warnings are unfounded.
There are a handful of proprietary objects or features that you can create or leverage to perform more advanced tasks:
- HANA-specific view types: Besides the standard database view that you maintain in the ABAP Dictionary (transaction SE11), the HANA database also provides a handful of proprietary view types that are optimized for performing various types of analytical operations. These proprietary view types include attribute, analytic, and calculation views.
- Decision tables: Decision tables allow you to model complex data-driven business rules in a reusable, callable format (similar to what’s provided with the BRF+ framework).
- Stored procedures: Stored procedures provide a mechanism for embedding custom application logic into the database. As the name suggests, the logic for a stored procedure is encoded in a parameterizable procedure module that combines imperative logic with SQL-based access to perform the requisite business tasks. In the HANA database, stored procedures are written in an SAP-proprietary scripting language called SQL Script. For certain types of business operations, stored procedures make sense. These procedures are always going to be faster than an ABAP-based alternative because they have direct access to the data (thus eliminating any latency associated with bringing the data back to the ABAP layer). In a way, stored procedures bridge the gap between what’s possible using pure SQL and what’s practical at the ABAP layer. For functions that are especially data intensive in nature, stored procedures are definitely worth a look.
- Search engine: In addition to its core query processor, the HANA database also provides a robust search engine that can be used to perform complex queries in a similar way that you might search on keywords using a search engine.
Some of these features can be accessed using pure SQL, whereas more advanced features are reserved for access via proprietary APIs or services. Collectively, these objects or features allow you to push more of the data-intensive business logic down to the database layer. On the ABAP side, you only need to push the right buttons to make all this work. Here, you have several options for accessing these features:
- ABAP Database Connectivity (ADBC): This API provides a robust, object-oriented alternative to the familiar EXEC SQL statement that was used to provide native access to the database. Using this API, you can invoke stored procedures.
- Database procedure proxies (new to SAP NetWeaver 7.40): In the SAP NetWeaver 7.40 release, SAP introduced a new development object that effectively wraps up a HANA stored procedure as a callable proxy object. These objects can then be invoked within ABAP programs using the new CALL DATABASE PROCEDURE statement.
- REST-based services: In addition to the core database-level features discussed in this article, HANA also offers another layer of functionality: the HANA Extended Application Services (HANA XS). Conceptually speaking, HANA XS introduces a thin Web application server on top of the HANA database, allowing you to encapsulate database accesses using open, REST-based Web services. These services can be consumed via HTTP within the ABAP layer, or even directly by Web or mobile applications based on the new SAPUI5 library.
Conclusion
There’s a lot to learn to fully grasp the power of HANA technology. This knowledge comes in due course, but in the meantime, the most important takeaway is that the HANA database eliminates the database-level bottleneck that has limited what you’ve been able to achieve with application designs before. With this bottleneck removed, you’re free to develop database-intensive logic in the way that makes the most sense.
Besides the obvious performance benefits, this revised approach should ultimately simplify your designs in the long run. For example, you can now delegate mundane processing tasks that can sometimes be difficult to carry out in the ABAP layer to the database (e.g., merging operations, sorting). You can also use the various built-in features of the database to verify the correctness of your query logic, tweak performance, and reduce network traffic. Once you realize that the database is your ally, everything changes for the better.

James Wood
James Wood is the founder and principal consultant of Bowdark Consulting, Inc., an SAP NetWeaver consulting and training organization. With more than 10 years of experience as a software engineer, James specializes in custom development in the areas of ABAP Objects, Java/J2EE, SAP NetWeaver Process Integration, and SAP NetWeaver Portal. Before starting Bowdark Consulting, Inc. in 2006, James was an SAP NetWeaver consultant for SAP America, Inc., and IBM Corporation, where he was involved in multiple SAP implementations. He holds a master’s degree in software engineering from Texas Tech University. He is also the author of Object-Oriented Programming with ABAP Objects (SAP PRESS, 2009), ABAP Cookbook (SAP PRESS, 2010), and SAP NetWeaver Process Integration: A Developer’s Guide (Bowdark Press, 2011). James is also a contributor to Advancing Your ABAP Skills, an anthology that holds a collection of articles recently published in SAP Professional Journal and BI Expert.
You may contact the author at jwood@bowdark.com.
If you have comments about this article or publication, or would like to submit an article idea, please contact the editor.




